博主
专辑
- javaweb专辑 2
- 学习笔记zg4 34
- hutool工具包的使用 13
- Vue3+Element Plus 12
- 跟着禹神学Vue3 1
- 学习笔记zg2(SpringBoot版) 10
- 学习笔记zg2-马 0
- LayUI专辑 14
- 学习笔记zg1 9
- java基础 1
第一节 Elasticsearch简介
1、简介

Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。
Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理,因为Lucene 非常复杂。
为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 编写,内部采用 Lucene 做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene 做了一层封装,它提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。
当然,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索;
- 一个分布式实时分析搜索引擎;
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据。
由于Elasticsearch的功能强大和使用简单,维基百科、卫报、Stack Overflow、GitHub等都纷纷采用它来做搜索。现在,Elasticsearch已成为全文搜索领域的主流软件之一。
官网网址:
# 英文
https://www.elastic.co
# 中文
https://www.elastic.co/cn/
2、Lucene与ES关系
1)Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
3、ES主要解决问题
1)检索相关数据;
2)返回统计结果;
3)速度要快。
4、工作原理

5、基本概念
1)、全文检索
全文搜索(Full-text Search)
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。
在全文搜索的世界中,存在着几个庞大的帝国,也就是主流工具,主要有:
- Apache Lucene
- Elasticsearch
- Solr
- Ferret
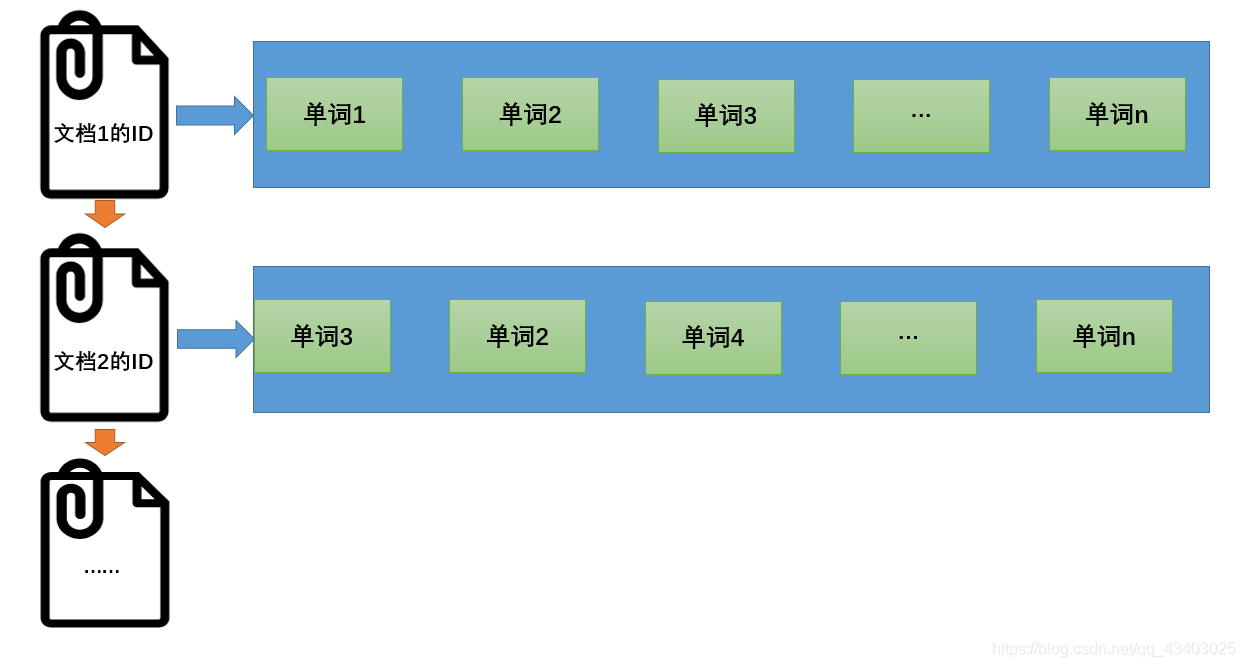
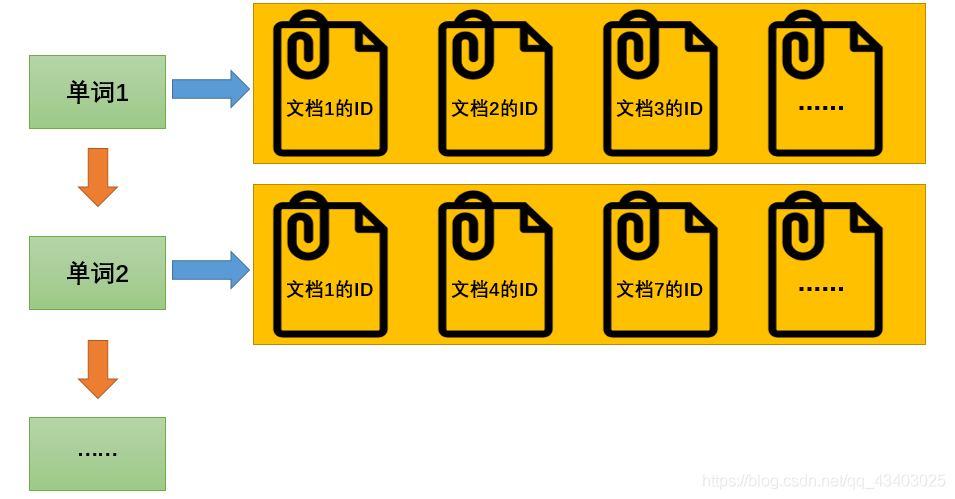
2)、倒排索引
倒排索引(Inverted Index)
该索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。**由于不是由记录来确定属性值,而是由属性值来确定记录的位置**,因而称为倒排索引(inverted index)。Elasticsearch能够实现快速、高效的搜索功能,正是基于倒排索引原理。

3)、节点和集群
节点 & 集群(Node & Cluster)
Elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个Elasticsearch实例。单个Elasticsearch实例称为一个节点(Node),一组节点构成一个集群(Cluster)。
4)、索引
索引(Index)
Elasticsearch 数据管理的顶层单位就叫做 Index(索引),相当于关系型数据库里的数据库的概念。另外,每个Index的名字必须是小写。
5)、文档
文档(Document)
Index里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。Document 使用 JSON 格式表示。同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
6)、类型
类型(Type)
Document 可以分组,比如employee这个 Index 里面,可以按部门分组,也可以按职级分组。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document,类似关系型数据库中的数据表。
不同的 Type 应该有相似的结构(Schema),性质完全不同的数据(比如 products 和 logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
7)、文档元数据
文档元数据(Document metadata)
文档元数据为_index, _type, _id, 这三者可以唯一表示一个文档,_index表示文档在哪存放,_type表示文档的对象类别,_id为文档的唯一标识。
8)、字段
字段(Fields)
每个Document都类似一个JSON结构,它包含了许多字段,每个字段都有其对应的值,多个字段组成了一个 Document,可以类比关系型数据库数据表中的字段。
在 Elasticsearch 中,文档(Document)归属于一种类型(Type),而这些类型存在于索引(Index)中,下图展示了Elasticsearch与传统关系型数据库的类比:

9)、分片
Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
10)、副本
Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
6、ELK是什么
ELK=elasticsearch+Logstash+kibana
elasticsearch:后台分布式存储以及全文检索
logstash: 日志加工、“搬运工”
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。