博主
专辑
- gradle专辑 1
- javaweb专辑 2
- 学习笔记zg4 33
- hutool工具包的使用 13
- Vue3+Element Plus 12
- 跟着禹神学Vue3 1
- 学习笔记zg2(SpringBoot版) 10
- 学习笔记zg2-马 0
- LayUI专辑 14
- 学习笔记zg1 9
第五节 线程池
1、线程池的优势
(1)、降低系统资源消耗,通过重用已存在的线程,降低线程创建和销毁造成的消耗;
(2)、提高系统响应速度,当有任务到达时,通过复用已存在的线程,无需等待新线程的创建便能立即执行;
(3)方便线程并发数的管控。因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM,并且会造成cpu过度切换(cpu切换线程是有时间成本的(需要保持当前执行线程的现场,并恢复要执行线程的现场))。
(4)提供更强大的功能,延时定时线程池。
1)、基本概念
- 线程池,本质上是一种对象池,用于管理线程资源。
- 在任务执行前,需要从线程池中拿出线程来执行。
- 在任务执行完成之后,需要把线程放回线程池。
- 通过线程的这种反复利用机制,可以有效地避免直接创建线程所带来的坏处。
2)、线程池带来了哪些好处。
降低资源的消耗。线程本身是一种资源,创建和销毁线程会有CPU开销;创建的线程也会占用一定的内存。
提高任务执行的响应速度。任务执行时,可以不必等到线程创建完之后再执行。
提高线程的可管理性。线程不能无限制地创建,需要进行统一的分配、调优和监控。
3)、不使用线程池有哪些坏处。
频繁的线程创建和销毁会占用更多的CPU和内存
频繁的线程创建和销毁会对GC产生比较大的压力
线程太多,线程切换带来的开销将不可忽视
线程太少,多核CPU得不到充分利用,是一种浪费
因此,我们有必要对线程池进行比较完整地说明,以便能对线程池进行正确地治理。
2、线程池的主要参数
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
(1)、corePoolSize(线程池基本大小):当向线程池提交一个任务时,若线程池已创建的线程数小于corePoolSize,即便此时存在空闲线程,也会通过创建一个新线程来执行该任务,直到已创建的线程数大于或等于corePoolSize时,(除了利用提交新任务来创建和启动线程(按需构造),也可以通过 prestartCoreThread() 或 prestartAllCoreThreads() 方法来提前启动线程池中的基本线程。)
(2)、maximumPoolSize(线程池最大大小):线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务。另外,对于无界队列,可忽略该参数。
(3)、keepAliveTime(线程存活保持时间)当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数。
但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
(4)、unit 参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
TimeUnit.DAYS; //天
TimeUnit.HOURS; //小时
TimeUnit.MINUTES; //分钟
TimeUnit.SECONDS; //秒
TimeUnit.MILLISECONDS; //毫秒
TimeUnit.MICROSECONDS; //微妙
TimeUnit.NANOSECONDS; //纳秒
(5)、workQueue(任务队列):用于传输和保存等待执行任务的阻塞队列。一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
- ArrayBlockingQueue;
- LinkedBlockingQueue;
- SynchronousQueue;
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和Synchronous。线程池的排队策略与BlockingQueue有关。
(6)、threadFactory(线程工厂):用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
(7)、handler(线程饱和策略):当线程池和队列都满了,再加入线程会执行此策略。表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
默认是ThreadPoolExecutor.AbortPolicy策略。
3、线程池流程
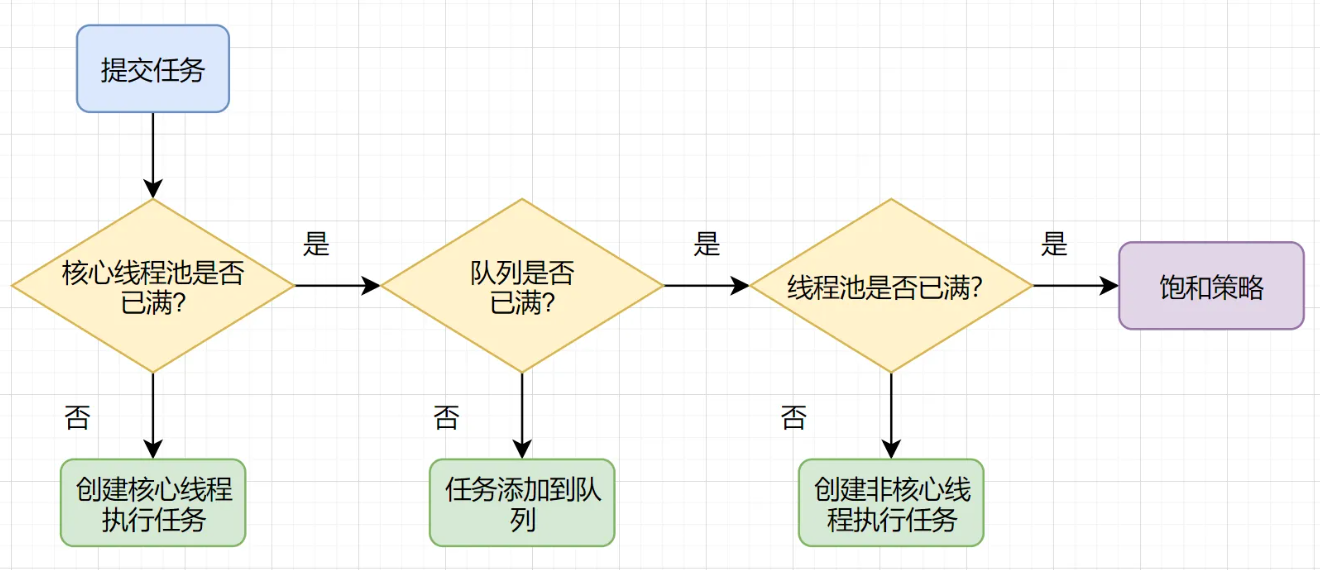
(1)、判断核心线程池是否已满,没满则创建一个新的工作线程来执行任务。已满则。
(2)、判断任务队列是否已满,没满则将新提交的任务添加在工作队列,已满则。
(3)、判断整个线程池是否已满,没满则创建一个新的工作线程来执行任务,已满则执行饱和策略。
(4)、判断线程池中当前线程数是否大于核心线程数,如果小于,在创建一个新的线程来执行任务,如果大于则
(5)、判断任务队列是否已满,没满则将新提交的任务添加在工作队列,已满则。
(6)、判断线程池中当前线程数是否大于最大线程数,如果小于,则创建一个新的线程来执行任务,如果大于,则执行饱和策略。)
4、线程池为什么需要使用(阻塞)队列?
回到了非线程池缺点中的第3点:
(1)、因为线程若是无限制的创建,可能会导致内存占用过多而产生OOM,并且会造成cpu过度切换。
另外回到了非线程池缺点中的第1点:
(2)、创建线程的消耗较高。
或者下面这个网上并不高明的回答:
(3)、线程池创建线程需要获取mainlock这个全局锁,影响并发效率,阻塞队列可以很好的缓冲。
5、线程池为什么要使用阻塞队列而不使用非阻塞队列?
阻塞队列可以保证任务队列中没有任务时阻塞获取任务的线程,使得线程进入wait状态,释放cpu资源。
当队列中有任务时才唤醒对应线程从队列中取出消息进行执行。
使得在线程不至于一直占用cpu资源。
(线程执行完任务后通过循环再次从任务队列中取出任务进行执行,代码片段如下
while (task != null || (task = getTask()) != null) {})。
不用阻塞队列也是可以的,不过实现起来比较麻烦而已,有好用的为啥不用呢?
6、如何配置线程池
-
CPU密集型任务
尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,会造成CPU过度切换。 -
IO密集型任务
可以使用稍大的线程池,一般为2*CPU核心数。 IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候有其他线程去处理别的任务,充分利用CPU时间。 -
混合型任务
可以将任务分成IO密集型和CPU密集型任务,然后分别用不同的线程池去处理。 只要分完之后两个任务的执行时间相差不大,那么就会比串行执行来的高效。
因为如果划分之后两个任务执行时间有数据级的差距,那么拆分没有意义。
因为先执行完的任务就要等后执行完的任务,最终的时间仍然取决于后执行完的任务,而且还要加上任务拆分与合并的开销,得不偿失。
7、java中提供的线程池
Executors类提供了4种不同的线程池:newCachedThreadPool, newFixedThreadPool, newScheduledThreadPool, newSingleThreadExecutor
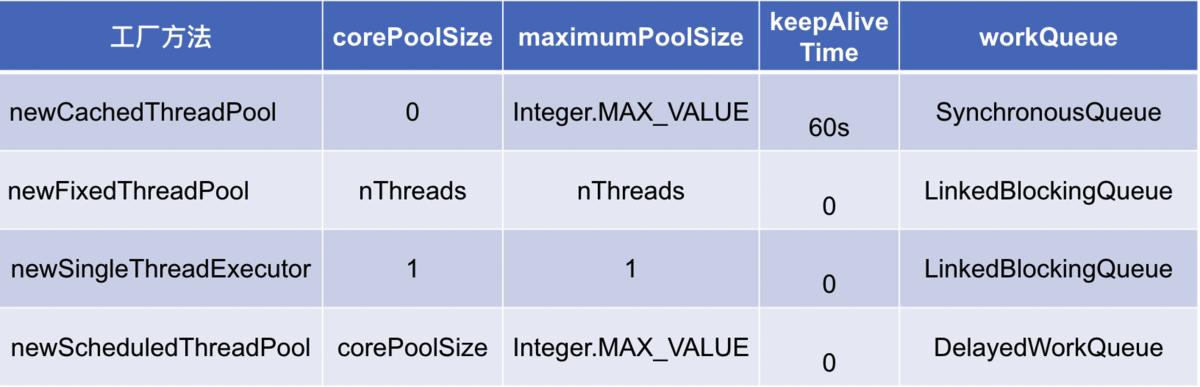
(1)、newCachedThreadPool:用来创建一个可以无限扩大的线程池,适用于负载较轻的场景,执行短期异步任务。(可以使得任务快速得到执行,因为任务时间执行短,可以很快结束,也不会造成cpu过度切换)
(2)、newFixedThreadPool:创建一个固定大小的线程池,因为采用无界的阻塞队列,所以实际线程数量永远不会变化,适用于负载较重的场景,对当前线程数量进行限制。(保证线程数可控,不会造成线程过多,导致系统负载更为严重)
(3)、newSingleThreadExecutor:创建一个单线程的线程池,适用于需要保证顺序执行各个任务。
(4)、newScheduledThreadPool:适用于执行延时或者周期性任务。
8、execute()和submit()方法
(1)、execute(),执行一个任务,没有返回值。
(2)、submit(),提交一个线程任务,有返回值。
submit(Callable task)能获取到它的返回值,通过future.get()获取(阻塞直到任务执行完)。一般使用FutureTask+Callable配合使用(IntentService中有体现)。
submit(Runnable task, T result)能通过传入的载体result间接获得线程的返回值。
submit(Runnable task)则是没有返回值的,就算获取它的返回值也是null。
Future.get方法会使取结果的线程进入阻塞状态,知道线程执行完成之后,唤醒取结果的线程,然后返回结果。
9、线程池示例
Executors
1)、单线程池
// 单个线程的线程池
public static void test1() {
ExecutorService threadpool = Executors.newSingleThreadExecutor();
for (int idx = 0; idx < 10; idx++) {
threadpool.execute(()->{
System.out.println(Thread.currentThread().getName() + ":OK");
});
}
}
2)、固定数量线程的线程池
// 固定数量的线程池
public static void test2() {
ExecutorService threadpool = Executors.newFixedThreadPool(5);
for (int idx = 0; idx < 100; idx++) {
threadpool.execute(()->{
System.out.println(Thread.currentThread().getName() + ":OK");
});
}
}
3)、可伸缩性的线程池
// 可伸缩性的线程池
public static void test3() {
ExecutorService threadpool = Executors.newCachedThreadPool();
for (int idx = 0; idx < 100; idx++) {
threadpool.execute(()->{
System.out.println(Thread.currentThread().getName() + ":OK");
});
}
threadpool.shutdown();
}
10、自定义线程池
@Test
public void testConsum() throws InterruptedException {
//--1
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(5));
//--2
for(int idx=0;idx<15;idx++){
executor.execute(()-> {
// try {
// Thread.sleep(100);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
System.out.println(Thread.currentThread().getName());
});
System.out.println("线程池中线程数目:"+executor.getPoolSize()+",队列中等待执行的任务数目:"+
executor.getQueue().size()+",已执行玩别的任务数目:"+executor.getCompletedTaskCount());
}
//
while(executor.getActiveCount()==10) {
Thread.sleep(1000);
}
//--3
executor.shutdown();
}