博主
专辑
- Cherry Markdown Editor 1
- 面试题 0
- 学习笔记zg5 10
- JAVA理论基础2025版 3
- 学习笔记 1
- DeepSeek+RAGFlow构建个人知识库 4
- 面试专辑2025版 7
- shixun1 7
- java学习历程 0
- java学习历程 0
第四节 SQL优化基础知识
1、SQL执行顺序
-
(8) SELECT(9) DISTINCT column,…
选择字段 、去重 -
(6) AGG_FUNC(column or expression),…
聚合函数 -
(1) FROM [left_table]
选择表 -
(3) JOIN
链接 -
(2) ON
链接条件 -
(4) WHERE
条件过滤 -
(5) GROUP BY
分组 -
(7) HAVING
分组过滤 -
(10) ORDER BY
排序 -
(11) LIMIT count OFFSET count;
分页
2、查询SQL尽量不要使用select *,而是具体字段
- 反例:
SELECT * FROM student
- 正例:
SELECT id,NAME FROM student
理由:
- 字段多时,大表能达到100多个字段甚至达200多个字段
- 只取需要的字段,节省资源、减少网络开销
- select * 进行查询时,很可能不会用到索引,就会造成全表扫描
3、避免在where子句中使用or来连接条件
查询id为1或者薪水为3000的用户:
- 反例:
SELECT * FROM student WHERE id=1 OR salary=30000
- 正例:
(1)使用union all
SELECT * FROM student WHERE id=1
UNION ALL
SELECT * FROM student WHERE salary=30000
(2)分开两条sql写
SELECT * FROM student WHERE id=1
SELECT * FROM student WHERE salary=30000
理由:
- 使用or可能会使索引失效,从而全表扫描
- 对于or没有索引的salary这种情况,假设它走了id的索引,但是走到salary查询条件时,它还得全表扫描。也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定。虽然mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引还是可能失效的
4、使用varchar代替char
- 反例:
`deptname` char(100) DEFAULT NULL COMMENT '部门名称'
- 正例:
`deptname` varchar(100) DEFAULT NULL COMMENT '部门名称'
理由:
- varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间
- char按声明大小存储,不足补空格
- 其次对于查询来说,在一个相对较小的字段内搜索,效率更高
5、尽量使用数值替代字符串类型
- 主键(id):primary key优先使用数值类型int,tinyint
- 性别(sex):0-代表女,1-代表男;数据库没有布尔类型,mysql推荐使用tinyint
- 支付方式(payment):1-现金、2-微信、3-支付宝、4-信用卡、5-银行卡
- 服务状态(state):1-开启、2-暂停、3-停止
- 商品状态(state):1-上架、2-下架、3-删除
6、查询尽量避免返回大量数据
- 如果查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。同时,大量数据返回也可能没有实际意义。如返回上千条甚至更多,用户也看不过来。
- 通常采用分页,一页习惯10/20/50/100条。
7、使用explain分析你SQL执行计划
SQL很灵活,一个需求可以很多实现,那哪个最优呢?SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引。
EXPLAIN
SELECT * FROM student WHERE id=1

8、是否使用了索引及其扫描类型
1)、type:
- ALL 全表扫描,没有优化,最慢的方式
- index 索引全扫描
- range 索引范围扫描,常用语<,<=,>=,between等操作
- ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
- eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
- const 当查询是对主键或者唯一键进行精确查询,系统会把匹配行中的其他列作为常数处理
- null MySQL不访问任何表或索引,直接返回结果
- System 表只有一条记录(实际中基本不存在这个情况)
性能排行:
System > const > eq_ref > ref > range > index > ALL
2)、possible_keys:
显示可能应用在这张表中的索引
3)、key
真正使用的索引方式
9、创建name字段的索引
提高查询速度的最简单最佳的方式
ALTER TABLE student ADD INDEX index_name (NAME)
10、优化like语句:
模糊查询,程序员最喜欢的就是使用like,但是like很可能让你的索引失效
- 反例:
EXPLAIN
SELECT id,NAME FROM student WHERE NAME LIKE '%1'
EXPLAIN
SELECT id,NAME FROM student WHERE NAME LIKE '%1%'
- 正例:
EXPLAIN
SELECT id,NAME FROM student WHERE NAME LIKE '1%'
1)、未使用索引:故意使用sex非索引字段
EXPLAIN
SELECT id,NAME FROM student WHERE NAME=1 OR sex=1

2)、主键索引生效
EXPLAIN
SELECT id,NAME FROM student WHERE id=1

3)、索引失效,type=ALL,全表扫描
EXPLAIN
SELECT id,NAME FROM student WHERE id LIKE '%1'
11、字符串怪现象
- 反例:
#未使用索引
EXPLAIN
SELECT * FROM student WHERE NAME=123
- 正例:
#使用索引
EXPLAIN
SELECT * FROM student WHERE NAME='123'
理由:
为什么第一条语句未加单引号就不走索引了呢?这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为数值类型再做比较
12、索引不宜太多,一般5个以内
- 索引并不是越多越好,虽其提高了查询的效率,但却会降低插入和更新的效率
- 索引可以理解为一个就是一张表,其可以存储数据,其数据就要占空间
- 再者,索引表的一个特点,其数据是排序的,那排序要不要花时间呢?肯定要
- insert或update时有可能会重建索引,如果数据量巨大,重建将进行记录的重新排序,所以建索引需要慎重考虑,视具体情况来定
- 一个表的索引数最好不要超过5个,若太多需要考虑一些索引是否有存在的必要
13、索引不适合建在有大量重复数据的字段上
如性别字段。因为SQL优化器是根据表中数据量来进行查询优化的,如果索引
列有大量重复数据,Mysql查询优化器推算发现不走索引的成本更低,很可能就放弃索引了。
14、where限定查询的数据
数据中假定就一个男的记录
- 反例:
SELECT id,NAME FROM student WHERE sex='男'
- 正例:
SELECT id,NAME FROM student WHERE id=1 AND sex='男'
理由:
需要什么数据,就去查什么数据,避免返回不必要的数据,节省开销
15、避免在索引列上使用内置函数
业务需求:查询最近七天内新生儿(用学生表替代下)
1)、给birthday字段创建索引:
ALTER TABLE student ADD INDEX idx_birthday (birthday)
2)、当前时间加7天:
SELECT NOW()
SELECT DATE_ADD(NOW(), INTERVAL 7 DAY)
3)、反例:
EXPLAIN
SELECT * FROM student
WHERE DATE_ADD(birthday,INTERVAL 7 DAY) >=NOW();
4)、正例:
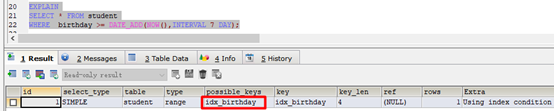
EXPLAIN
SELECT * FROM student
WHERE birthday >= DATE_ADD(NOW(),INTERVAL 7 DAY);
5)、理由:
-
使用索引列上内置函数
-
索引失效:
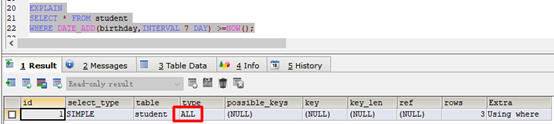
- 索引有效:
16、避免在where中对字段进行表达式操作
- 反例:
EXPLAIN
SELECT * FROM student WHERE id+1-1=+1
- 正例:
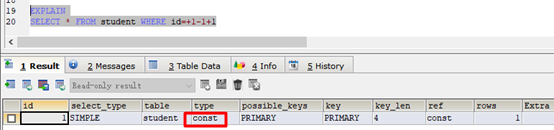
EXPLAIN
SELECT * FROM student WHERE id=+1-1+1
EXPLAIN
SELECT * FROM student WHERE id=1
理由:
- SQL解析时,如果字段相关的是表达式就进行全表扫描
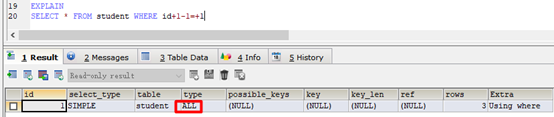
- 字段干净无表达式,索引生效
17、避免在where子句中使用!=或<>操作符
应尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。记住实现业务优先,实在没办法,就只能使用,并不是不能使用。如果不能使用,SQL也就无需支持了。
- 反例:
EXPLAIN
SELECT * FROM student WHERE salary!=3000
EXPLAIN
SELECT * FROM student WHERE salary<>3000
理由:
使用!=和<>很可能会让索引失效

18、去重distinct过滤字段要少
# 索引失效
EXPLAIN
SELECT DISTINCT * FROM student
# 索引生效
EXPLAIN
SELECT DISTINCT id,NAME FROM student
# 索引生效
EXPLAIN
SELECT DISTINCT NAME FROM student
理由:
带distinct的语句占用cpu时间高于不带distinct的语句。因为当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较、过滤的过程会占用系统资源,如cpu时间
19、where中使用默认值代替null
- 环境准备:
#修改表,增加age字段,类型int,非空,默认值0
ALTER TABLE student ADD age INT NOT NULL DEFAULT 0;
#修改表,增加age字段的索引,名称为idx_age
ALTER TABLE student ADD INDEX idx_age (age);
- 反例:
EXPLAIN
SELECT * FROM student WHERE age IS NOT NULL
- 正例:
EXPLAIN
SELECT * FROM student WHERE age>0
理由:
- 并不是说使用了is null 或者 is not null 就会不走索引了,这个跟mysql版本以及查询成本都有关
- 如果mysql优化器发现,走索引比不走索引成本还要高,就会放弃索引,这些条件 !=,<>,is null,is not null经常被认为让索引失效,其实是因为一般情况下,查询的成本高,优化器自动放弃索引的
- 如果把null值,换成默认值,很多时候让走索引成为可能,同时,表达意思也相对清晰一点