博主
258
258
258
258
专辑
- javaweb专辑 2
- 学习笔记zg4 34
- hutool工具包的使用 13
- Vue3+Element Plus 12
- 跟着禹神学Vue3 1
- 学习笔记zg2(SpringBoot版) 10
- 学习笔记zg2-马 0
- LayUI专辑 14
- 学习笔记zg1 9
- java基础 1
第五节 高级SQL优化
亮子
2022-09-17 07:47:03
10614
0
0
0
1、批量插入性能提升
大量数据提交,上千,上万,批量性能非常快,mysql独有
- 多条提交:
INSERT INTO student (id,NAME) VALUES(4,'name1');
INSERT INTO student (id,NAME) VALUES(5,'name2');
- 批量提交:
INSERT INTO student (id,NAME) VALUES(4,'name1'),(5,'name2');
理由:
- 默认新增SQL有事务控制,导致每条都需要事务开启和事务提交;而批量处理是一次事务开启和提交。自然速度飞升
- 数据量小体现不出来
2、批量删除优化
避免同时修改或删除过多数据,因为会造成cpu利用率过高,会造成锁表操作,从而影响别人对数据库的访问。
- 反例:
#一次删除10万或者100万+?
delete from student where id <100000;
#采用单一循环操作,效率低,时间漫长
for(User user:list){
delete from student;
}
- 正例:
#分批进行删除,如每次500
for(){
delete student where id<500;
}
delete student where id>=500 and id<1000;
理由:
一次性删除太多数据,可能造成锁表,会有lock wait timeout exceed的错误,所以建议分批操作
3、伪删除设计
商品状态(state):1-上架、2-下架、3-删除
理由:
- 这里的删除只是一个标识,并没有从数据库表中真正删除,可以作为历史记录备查
- 同时,一个大型系统中,表关系是非常复杂的,如电商系统中,商品作废了,但如果直接删除商品,其它商品详情,物流信息中可能都有其引用。
- 通过where state=1或者where state=2过滤掉数据,这样伪删除的数据用户就看不到了,从而不影响用户的使用
- 操作速度快,特别数据量很大情况下
4、提高group by语句的效率
可以在执行到该语句前,把不需要的记录过滤掉
反例:先分组,再过滤
select job,avg(salary) from employee
group by job
having job ='president' or job = 'managent';
正例:先过滤,后分组
select job,avg(salary) from employee
where job ='president' or job = 'managent'
group by job;
5、复合索引最左匹配原则
创建复合索引,也就是多个字段
ALTER TABLE student ADD INDEX idx_name_salary (NAME,salary)
满足复合索引的左侧顺序,哪怕只是部分,复合索引生效
EXPLAIN
SELECT * FROM student WHERE NAME='name1'
没有出现左边的字段,则不满足最左特性,索引失效
EXPLAIN
SELECT * FROM student WHERE salary=3000
复合索引全使用,按左侧顺序出现 name,salary,索引生效
EXPLAIN
SELECT * FROM student WHERE NAME='陈子枢' AND salary=3000
虽然违背了最左特性,但MYSQL执行SQL时会进行优化,底层进行颠倒优化
EXPLAIN
SELECT * FROM student WHERE salary=3000 AND NAME='name1'
理由:
- 复合索引也称为联合索引
- 当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则
- 联合索引不满足最左原则,索引一般会失效,但是这个还跟Mysql优化器有关的
6、排序字段创建索引
什么样的字段才需要创建索引呢?原则就是where和order by中常出现的字段就创建索引。
#使用*,包含了未索引的字段,导致索引失效
EXPLAIN
SELECT * FROM student ORDER BY NAME;
EXPLAIN
SELECT * FROM student ORDER BY NAME,salary
#name字段有索引
EXPLAIN
SELECT id,NAME FROM student ORDER BY NAME
#name和salary复合索引
EXPLAIN
SELECT id,NAME FROM student ORDER BY NAME,salary
EXPLAIN
SELECT id,NAME FROM student ORDER BY salary,NAME
#排序字段未创建索引,性能就慢
EXPLAIN
SELECT id,NAME FROM student ORDER BY sex
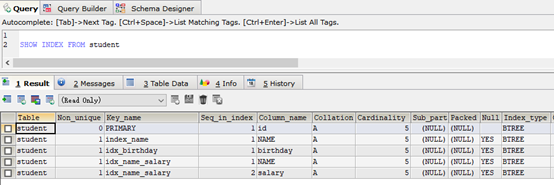
7、删除冗余和重复的索引
SHOW INDEX FROM student
#创建索引index_name
ALTER TABLE student ADD INDEX index_name (NAME)
#删除student表的index_name索引
DROP INDEX index_name ON student ;
#修改表结果,删除student表的index_name索引
ALTER TABLE student DROP INDEX index_name ;
#主键会自动创建索引,删除主键索引
ALTER TABLE student DROP PRIMARY KEY ;
8、不要有超过5个以上的表连接
- 关联的表个数越多,编译的时间和开销也就越大
- 每次关联内存中都生成一个临时表
- 应该把连接表拆开成较小的几个执行,可读性更高
- 如果一定需要连接很多表才能得到数据,那么意味着这是个糟糕的设计了
- 阿里规范中,建议多表联查三张表以下
9、inner join 、left join、right join,优先使用inner join
三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
- inner join 内连接,只保留两张表中完全匹配的结果集
- left join会返回左表所有的行,即使在右表中没有匹配的记录
- right join会返回右表所有的行,即使在左表中没有匹配的记录
理由:
- 如果inner join是等值连接,返回的行数比较少,所以性能相对会好一点
- 同理,使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少。这是mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优
10、in子查询的优化
日常开发实现业务需求可以有两种方式实现:
- 一种使用数据库SQL脚本实现
- 一种使用程序实现
如需求:查询所有部门的所有员工:
#in子查询
SELECT * FROM tb_user WHERE dept_id IN (SELECT id FROM tb_dept);
#这样写等价于:
#先查询部门表
SELECT id FROM tb_dept
#再由部门dept_id,查询tb_user的员工
SELECT * FROM tb_user u,tb_dept d WHERE u.dept_id = d.id
假设表A表示某企业的员工表,表B表示部门表,查询所有部门的所有员工,很容易有以下程序实现,可以抽象成这样的一个嵌套循环:
List<> resultSet;
for(int i=0;i<B.length;i++) {
for(int j=0;j<A.length;j++) {
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
上面的需求使用SQL就远不如程序实现,特别当数据量巨大时。
理由:
数据库最费劲的就是程序链接的释放。假设链接了两次,每次做上百万次的数据集查询,查完就结束,这样就只做了两次;相反建立了上百万次链接,申请链接释放反复重复,就会额外花费很多实际,这样系统就受不了了,慢,卡顿
11、尽量使用union all替代union
反例:
SELECT * FROM student
UNION
SELECT * FROM student
正例:
SELECT * FROM student
UNION ALL
SELECT * FROM student
理由:
- union和union all的区别是,union会自动去掉多个结果集合中的重复结果,而union all则将所有的结果全部显示出来,不管是不是重复
- union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序
- union在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION