博主
专辑
- 跟着禹神学Vue3 1
- Vue3+Element Plus 12
- hutool工具包的使用 13
- 学习笔记zg4 26
- javaweb专辑 2
- gradle专辑 1
- 学习笔记zg2 25
- LeetCode学习 1
- Redisson分布式锁架构 4
- 学习笔记zg6 4
- java面试问题扩充 1
- 消息中间件学习 3
- 学习笔记20230815 11
- Vue3编程专辑 3
- 图片 1
- JVM诊断调优工具Arthas 教程到实战 8
- AOP专辑 3
- ChatGPT问答专辑 4
- kafka 1
- HBase数据库专辑 6
- 第三方接口访问方法 5
- 课堂笔记 1
- 分布式文件存储系统MinIO 5
- Linux运维与安全 4
- Kubernetes专辑 2
- 11 1
- VMWare使用专辑 3
- 线程池 1
- Spring面试 1
- Mycat 2
- Spring 自定义注解与Aop 2
- FFmpeg 1
- ElasticSearch 1
- 面试八股文 5
- mysql 1
- Mybatis 1
- docker 1
- vscode开发vue程序的环境配置 3
- DFA 算法实现的高性能 java 敏感词工具框架sensitive-word 3
- 随心笔记 4
- kafka入门专辑 7
- Websocket专辑 2
- Sentinel专辑 7
- 支付宝支付专辑 3
- Java错误集锦 5
- Web Uploader大文件上传专辑 4
- Mybatis 与 MybatisPlus 专辑 4
- oracle 1
- 达梦数据库 1
- 若依框架专辑 4
- FreeMarker专辑 6
- 电商专辑 1
- 专辑 2
- JAVA十八罗汉 1
- SQL优化专题 6
- MyCat专辑 2
- 简单思考 1
- 学习文档 22
- 腾讯云直播专辑 9
- Skywalking链路追踪 3
- Java面试问题专辑 12
- Java常用工具类专辑 10
- java基础技术及功能 2
- PDF专辑 2
- 网站接入第三方微信扫码登录 3
- Seata分布式事务专辑 2
- Activiti工作流专辑 2
- Linux 1
- Mybatis和MybatisPlus杂记 1
- JMeter专辑 2
- 阿里直播专辑 1
- 面试专辑-数据库篇 1
- 微信登录专辑 1
- MySQL编程指南 3
- Jsoup专辑 6
- MySQL专辑 1
- Apache AB入门 3
- Spring事务专辑 3
- 数据库 1
- 算法 2
- Thymeleaf模版专辑 13
- Java数据加密专辑 4
- Spring框架入门教程 2
- maven专题 6
- JVM专题 9
- 面试专辑高级篇 15
- 面试专辑基础篇 15
- SpringBoot集成Excel的导入导出功能 2
- java设计模式 2
- Apache ECharts使用入门 9
- 分布式框架之zookeeper+dubbo 8
- Java面试专辑 2
- Excel 3
- 微信支付入门 18
- SpringCloud-Alibaba入门专辑 14
- Linux服务器环境配置专辑 8
- SpringCloud-Alibaba 3
- redis葵花宝典 4
- nginx服务器系列 9
- FastDFS专辑 4
- 参码电商平台系统 3
- RabbitMQ由入门到精通 11
- mybatis -plus 7
- IDEA使用技能专辑 10
- MongoDB专辑 6
- Elasticsearch专辑 20
- SSM框架 5
- Redis编程指南 1
- Linux系统常用命令的使用 0
- SpringSecurity安全框架 7
- SpringBoot集成Redis编程 4
- Redis入门专辑 28
- Vue编程专辑 39
- 文件上传到阿里云OSS实战 4
- git源码管理专题 12
- HTTP协议简析 4
- Docker环境搭建专辑 32
- SpringBoot微服务编程专辑 51
- SpringCloud微服务架构 20
- svn源码管理专题 0
- Oracle编程指南 0
- Json编程指南 0
- Spring 实战 0
- 华为高斯(GaussDB)数据库专辑 0
- SpringBoot中的Thymeleaf模板入门 0
- 搭建Window的开发环境 0
- Java语言开发笔记 0
- 微信登录接口专辑 0
第一节 kafka简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
主要特性
Kafka 是一种高吞吐量 的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
相关术语
- “Broker” Kafka集群包含一个或多个服务器,这种服务器被称为broker [5]
- “Topic” 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- “Partition” Partition是物理上的概念,每个Topic包含一个或多个Partition.
- “Producer” 负责发布消息到Kafka broker
- “Consumer” 消息消费者,向Kafka broker读取消息的客户端。
- “Consumer Group” 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于 大数据实时处理领域。
消息队列
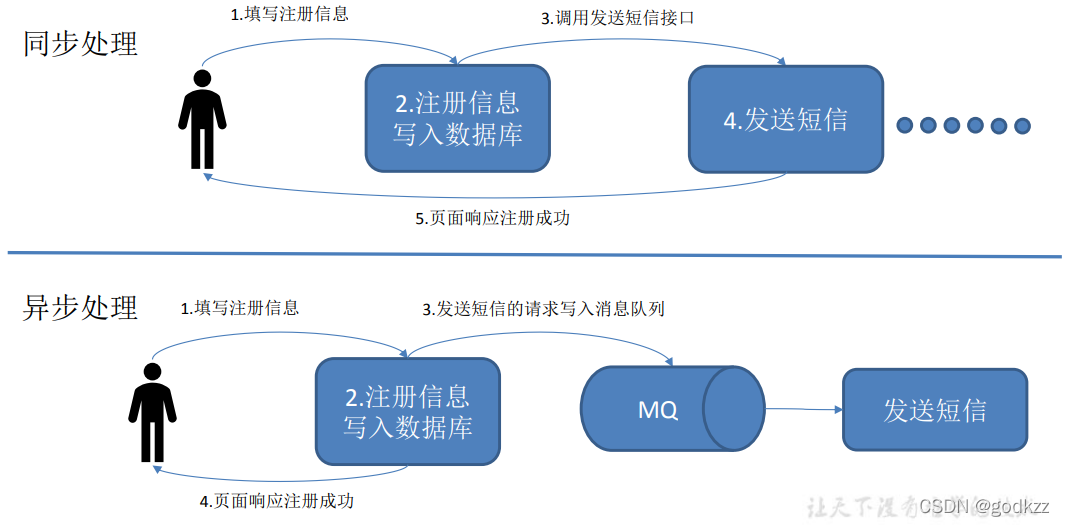
使用消息队列的好处
1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所 以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致 的情况。
4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列 能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户 把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要 的时候再去处理它们。
消息队列的两种模式
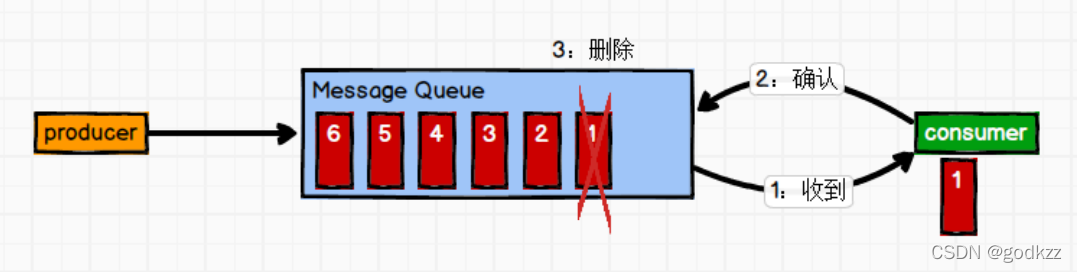
1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。 消息被消费以后,queue 中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue 支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
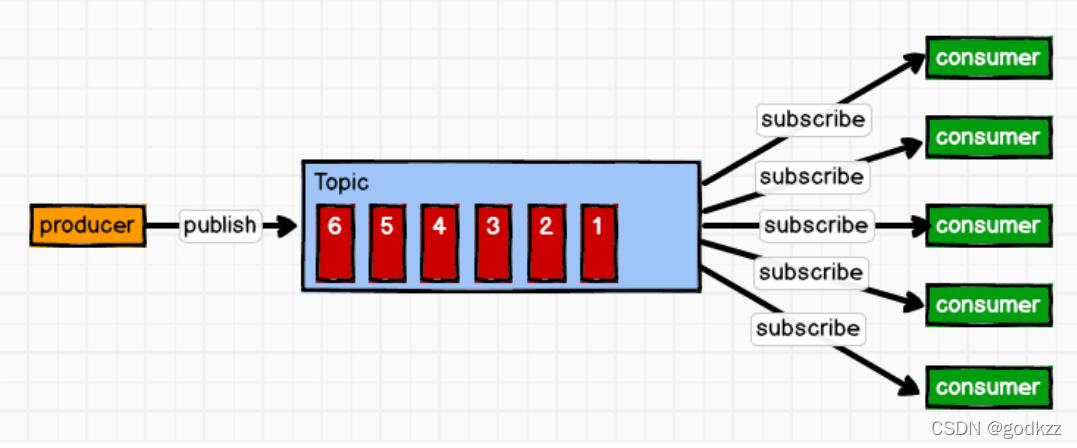
2)发布/订阅模式 (一对多,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消 息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
Kafka基础架构
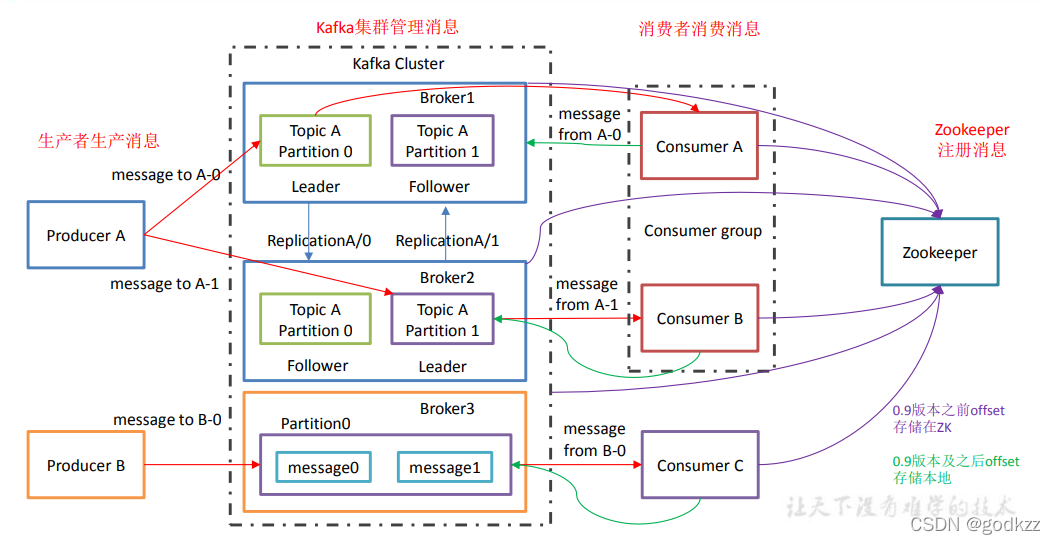
1)Producer :消息生产者,就是向 kafka broker 发消息的客户端;
2)Consumer :消息消费者,向 kafka broker 取消息的客户端;
3)Consumer Group (CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负 责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所 有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
4)Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
5)Topic :可以理解为一个队列,生产者和消费者面向的都是一个 topic;
6)Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上, 一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列;
7)Replica:副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本, 一个 leader 和若干个 follower。
8)leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对 象都是 leader。
9)follower:每个分区多个副本中的“从”,实时从 leader 中同步数据,保持和 leader 数据 的同步。leader 发生故障时,某个 follower 会成为新的 follower。