博主
258
258
258
258
专辑
- javaweb专辑 2
- 学习笔记zg4 34
- hutool工具包的使用 13
- Vue3+Element Plus 12
- 跟着禹神学Vue3 1
- 学习笔记zg2(SpringBoot版) 10
- 学习笔记zg2-马 0
- LayUI专辑 14
- 学习笔记zg1 9
- java基础 1
第十五节 ES聚合查询-springboot整合es的聚合查询
亮子
2024-03-05 01:54:30
19475
0
0
0
第09单元-ES聚合查询-01-springboot整合es的聚合查询
项目需求:
系统平台管理员,需要统计注册用户的平均年龄等统计信息。
需求描述:
系统平台为了完成对用户群体画像,必须对注册的用户信息进行统计。其中统计注册用户的平均年龄,以及男女的平均年龄信息,并在后台展示。
1、创建表
/*
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50727
Source Host : localhost:3306
Source Schema : db_shop_1912
Target Server Type : MySQL
Target Server Version : 50727
File Encoding : 65001
Date: 08/07/2022 19:06:38
*/
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tb_book
-- ----------------------------
DROP TABLE IF EXISTS `tb_book`;
CREATE TABLE `tb_book` (
`book_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '图书ID',
`book_name` varchar(80) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '书名',
`book_type` int(11) NULL DEFAULT 0 COMMENT '图书类型',
`book_price` int(11) NULL DEFAULT 0 COMMENT '图书价格',
`deleted` int(2) NULL DEFAULT 0 COMMENT '删除状态0:未删除,1:已删除',
`create_time` datetime(0) NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime(0) NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP(0) COMMENT '更新时间',
PRIMARY KEY (`book_id`) USING BTREE,
INDEX `book_name`(`book_name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '图书表' ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of tb_book
-- ----------------------------
INSERT INTO `tb_book` VALUES (1, '程序员的自我修养', 1, 10, 0, '2022-07-08 17:42:24', '2022-07-08 17:42:24');
INSERT INTO `tb_book` VALUES (2, 'MySQL从入门到跑路', 2, 15, 0, '2022-07-08 17:42:50', '2022-07-08 17:43:33');
INSERT INTO `tb_book` VALUES (3, '富婆的人性弱点', 1, 22, 0, '2022-07-08 17:43:29', '2022-07-08 17:43:29');
INSERT INTO `tb_book` VALUES (4, '借钱的能力', 1, 50, 0, '2022-07-08 17:44:12', '2022-07-08 17:44:12');
SET FOREIGN_KEY_CHECKS = 1;
2、定义实体类
package com.shenmazong.user.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import java.io.Serializable;
import java.util.Date;
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
* 图书表
* @TableName tb_book
*/
@TableName(value ="tb_book")
@Data
@Document(indexName = "tb_book")
public class TbBook implements Serializable {
/**
* 图书ID
*/
@TableId(type = IdType.AUTO)
@Id
private Integer bookId;
/**
* 书名
*/
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String bookName;
/**
* 图书类型
*/
@Field(type = FieldType.Integer)
private Integer bookType;
/**
* 图书价格
*/
@Field(type = FieldType.Integer)
private Integer bookPrice;
/**
* 删除状态0:未删除,1:已删除
*/
@Field(type = FieldType.Integer)
private Integer deleted;
/**
* 创建时间
*/
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone="GMT+8")
private Date createTime;
/**
* 更新时间
*/
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(pattern="yyyy-MM-dd HH:mm:ss",timezone="GMT+8")
private Date updateTime;
@TableField(exist = false)
private static final long serialVersionUID = 1L;
}
3、创建索引并导入数据
@SpringBootTest
class ServerShopUserApplicationTests {
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
TbBookMapper tbBookMapper;
@Test
void create() {
if(elasticsearchRestTemplate.indexOps(TbBook.class).exists()) {
return;
}
elasticsearchRestTemplate.indexOps(TbBook.class).create();
Document mapping = elasticsearchRestTemplate.indexOps(TbBook.class).createMapping();
elasticsearchRestTemplate.indexOps(TbBook.class).putMapping(mapping);
List<TbBook> tbBooks = tbBookMapper.selectList(null);
elasticsearchRestTemplate.save(tbBooks);
}
}
4、聚合查询
1)、分组统计
相当于如下SQL语句:
select bookType,count(*) as cnt from tb_book group by bookType
@Test
void testGroup() {
// count 为数据的别名
TermsAggregationBuilder agg = AggregationBuilders.terms("cnt").field("bookType");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
Terms bookType = searchHits.getAggregations().get("cnt");
List<? extends Terms.Bucket> buckets = bookType.getBuckets();
buckets.forEach(item -> {
System.out.println(item.getKeyAsString());
long docCount = item.getDocCount();
System.out.println(docCount);
});
}
- 输出结果
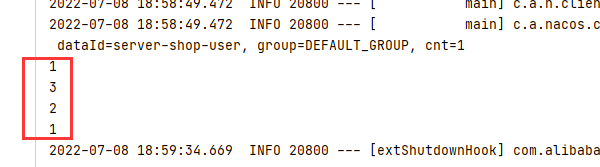
2)、求最小值
select min(bookPrice) from tb_book
@Test
void testMin() {
MinAggregationBuilder agg = AggregationBuilders.min("minPrice").field("bookPrice");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
Aggregations aggregations = searchHits.getAggregations();
Min minPrice = aggregations.get("minPrice");
double value = minPrice.getValue();
System.out.println("minPrice="+value);
}
- 输出结果
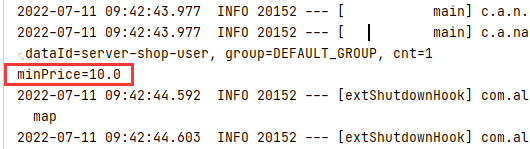
3)、求最大值
select max(bookPrice) from tb_book
@Test
void testMax() {
MaxAggregationBuilder agg = AggregationBuilders.max("maxPrice").field("bookPrice");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
Aggregations aggregations = searchHits.getAggregations();
Max maxPrice = aggregations.get("maxPrice");
double value = maxPrice.getValue();
System.out.println("maxPrice="+value);
}
4)、求和
select sum(bookPrice) from tb_book
@Test
void testSum() {
SumAggregationBuilder agg = AggregationBuilders.sum("sumPrice").field("bookPrice");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
Aggregations aggregations = searchHits.getAggregations();
Sum sumPrice = aggregations.get("sumPrice");
double value = sumPrice.getValue();
System.out.println("==============");
System.out.println("sumPrice="+value);
System.out.println("==============");
}
- 运行结果
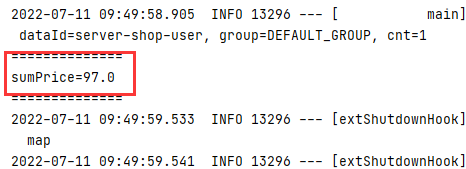
5)、求平均值
select avg(bookPrice) from tb_book
@Test
void testAvg() {
AvgAggregationBuilder agg = AggregationBuilders.avg("avgPrice").field("bookPrice");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
Aggregations aggregations = searchHits.getAggregations();
Avg avgPrice = aggregations.get("avgPrice");
double value = avgPrice.getValue();
System.out.println("==============");
System.out.println("avgPrice="+value);
System.out.println("==============");
}
- 运行结果
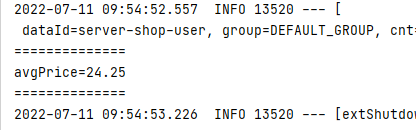
6)、求记录数
select count(*) from tb_book
@Test
void testCount() {
ValueCountAggregationBuilder agg = AggregationBuilders.count("agg").field("bookType");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
ValueCount valueCount = searchHits.getAggregations().get("agg");
long count = valueCount.getValue();
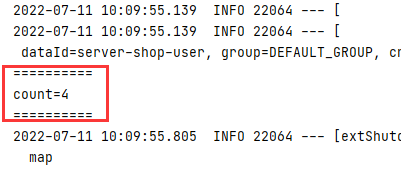
System.out.println("==========");
System.out.println("count="+count);
System.out.println("==========");
}
- 运行结果
7)、使用聚合反应
@Test
void testStats() {
StatsAggregationBuilder agg = AggregationBuilders.stats("statsPrice").field("bookPrice");
NativeSearchQuery build = new NativeSearchQueryBuilder().addAggregation(agg).withPageable(PageRequest.of(0, 10)).build();
SearchHits<TbBook> searchHits = elasticsearchRestTemplate.search(build, TbBook.class);
Aggregations aggregations = searchHits.getAggregations();
Stats statsPrice = aggregations.get("statsPrice");
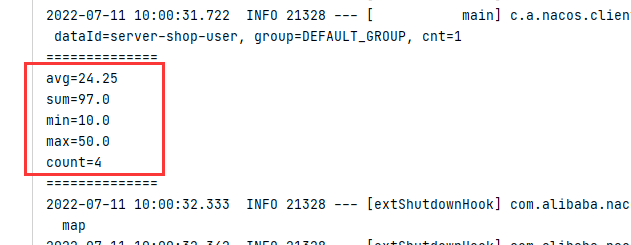
System.out.println("==============");
System.out.println("avg="+statsPrice.getAvgAsString());
System.out.println("sum="+statsPrice.getSumAsString());
System.out.println("min="+statsPrice.getMinAsString());
System.out.println("max="+statsPrice.getMaxAsString());
System.out.println("count="+statsPrice.getCount());
System.out.println("==============");
}
- 运行结果
聚合桶查询
在Spring Boot中使用Elasticsearch实现分组统计可以通过Elasticsearch的聚合(Aggregation)功能来实现。具体步骤如下:
- 首先,在Spring Boot项目中引入Elasticsearch的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 创建一个Elasticsearch Repository 接口,用于定义 Elasticsearch 的查询方法:
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface YourElasticsearchRepository extends ElasticsearchRepository<YourEntity, String> {
// 可以定义一些自定义的查询方法
}
- 创建一个 Service 类,编写方法实现分组统计逻辑:
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.sum.SumAggregationBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.stereotype.Service;
@Service
public class YourElasticsearchService {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
public void groupAndAggregate() {
TermsAggregationBuilder aggregation = AggregationBuilders.terms("group_by_field").field("your_field.keyword")
.subAggregation(AggregationBuilders.sum("sum_of_field").field("your_numeric_field"));
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery())
.addAggregation(aggregation)
.build();
AggregatedPage<YourEntity> aggregatedPage = elasticsearchRestTemplate.queryForPage(searchQuery, YourEntity.class);
Terms groupByField = aggregatedPage.getAggregations().get("group_by_field");
for (Terms.Bucket bucket : groupByField.getBuckets()) {
String key = bucket.getKeyAsString();
Sum sumAgg = bucket.getAggregations().get("sum_of_field");
double sumValue = sumAgg.getValue();
// 在这里处理统计结果
}
}
}
在上面的代码中,YourEntity 是你的实体类,your_field 和 your_numeric_field 分别是你要进行分组统计的字段和需要统计的数值字段。
- 最后,在 Controller 中调用 Service 方法即可:
@RestController
public class YourController {
@Autowired
private YourElasticsearchService elasticsearchService;
@GetMapping("/groupAndAggregate")
public void groupAndAggregate() {
elasticsearchService.groupAndAggregate();
}
}
以上就是在Spring Boot项目中使用Elasticsearch实现分组统计的简单示例。你可以根据具体的业务需求和数据结构进行相应的调整和扩展。