博主
专辑
- 跟着禹神学Vue3 1
- Vue3+Element Plus 12
- hutool工具包的使用 13
- 学习笔记zg4 26
- javaweb专辑 2
- gradle专辑 1
- 学习笔记zg2 25
- LeetCode学习 1
- Redisson分布式锁架构 4
- 学习笔记zg6 4
- java面试问题扩充 1
- 消息中间件学习 3
- 学习笔记20230815 11
- Vue3编程专辑 3
- 图片 1
- JVM诊断调优工具Arthas 教程到实战 8
- AOP专辑 3
- ChatGPT问答专辑 4
- kafka 1
- HBase数据库专辑 6
- 第三方接口访问方法 5
- 课堂笔记 1
- 分布式文件存储系统MinIO 5
- Linux运维与安全 4
- Kubernetes专辑 2
- 11 1
- VMWare使用专辑 3
- 线程池 1
- Spring面试 1
- Mycat 2
- Spring 自定义注解与Aop 2
- FFmpeg 1
- ElasticSearch 1
- 面试八股文 5
- mysql 1
- Mybatis 1
- docker 1
- vscode开发vue程序的环境配置 3
- DFA 算法实现的高性能 java 敏感词工具框架sensitive-word 3
- 随心笔记 4
- kafka入门专辑 7
- Websocket专辑 2
- Sentinel专辑 7
- 支付宝支付专辑 3
- Java错误集锦 5
- Web Uploader大文件上传专辑 4
- Mybatis 与 MybatisPlus 专辑 4
- oracle 1
- 达梦数据库 1
- 若依框架专辑 4
- FreeMarker专辑 6
- 电商专辑 1
- 专辑 2
- JAVA十八罗汉 1
- SQL优化专题 6
- MyCat专辑 2
- 简单思考 1
- 学习文档 22
- 腾讯云直播专辑 9
- Skywalking链路追踪 3
- Java面试问题专辑 12
- Java常用工具类专辑 10
- java基础技术及功能 2
- PDF专辑 2
- 网站接入第三方微信扫码登录 3
- Seata分布式事务专辑 2
- Activiti工作流专辑 2
- Linux 1
- Mybatis和MybatisPlus杂记 1
- JMeter专辑 2
- 阿里直播专辑 1
- 面试专辑-数据库篇 1
- 微信登录专辑 1
- MySQL编程指南 3
- Jsoup专辑 6
- MySQL专辑 1
- Apache AB入门 3
- Spring事务专辑 3
- 数据库 1
- 算法 2
- Thymeleaf模版专辑 13
- Java数据加密专辑 4
- Spring框架入门教程 2
- maven专题 6
- JVM专题 9
- 面试专辑高级篇 15
- 面试专辑基础篇 15
- SpringBoot集成Excel的导入导出功能 2
- java设计模式 2
- Apache ECharts使用入门 9
- 分布式框架之zookeeper+dubbo 8
- Java面试专辑 2
- Excel 3
- 微信支付入门 18
- SpringCloud-Alibaba入门专辑 14
- Linux服务器环境配置专辑 8
- SpringCloud-Alibaba 3
- redis葵花宝典 4
- nginx服务器系列 9
- FastDFS专辑 4
- 参码电商平台系统 3
- RabbitMQ由入门到精通 11
- mybatis -plus 7
- IDEA使用技能专辑 10
- MongoDB专辑 6
- Elasticsearch专辑 20
- SSM框架 5
- Redis编程指南 1
- Linux系统常用命令的使用 0
- SpringSecurity安全框架 7
- SpringBoot集成Redis编程 4
- Redis入门专辑 28
- Vue编程专辑 39
- 文件上传到阿里云OSS实战 4
- git源码管理专题 12
- HTTP协议简析 4
- Docker环境搭建专辑 32
- SpringBoot微服务编程专辑 51
- SpringCloud微服务架构 20
- svn源码管理专题 0
- Oracle编程指南 0
- Json编程指南 0
- Spring 实战 0
- 华为高斯(GaussDB)数据库专辑 0
- SpringBoot中的Thymeleaf模板入门 0
- 搭建Window的开发环境 0
- Java语言开发笔记 0
- 微信登录接口专辑 0
第十九节 ES聚合查询-es的source源如何同步的原理
第10单元-ES聚合查询-05-es的source源如何同步的原理
项目需求:
对于几千万的注册用户,发布的朋友圈的数据是海量的,需要能够搜索,同时也要完成可用性。
需求描述:
对于几千万的注册用户,发布的朋友圈的数据是海量的,需要能够搜索,同时也要完成可用性。第一个要求是大量的朋友圈数据,需要存储到分布式集群中,给出解决方案。另外,在服务器突然宕机的情况,仍然能够保障搜索业务不中断,不少数据。同时要充分利用底层的数据同步原理,提高数据的稳定性。
路由文档到分片
1、文档路由到分片上:一个索引由多个分片构成,当添加(删除、修改)一个文档时,Elasticsearch就需要决定这个文档存储在哪个分片上,这个过程就称为数据路由(routing)。
2、路由算法:
shard = hash(routing) % number_of_primary_shards
示例:一个索引,3个 primary shard
- 每次增删改查时,都有一个 routing 值,默认是文档的 _id 的值。
- 对这个 routing 值使用 hash 函数进行计算。
- 计算出的值再和主分片个数取余数,余数的取值范围永远是(0 ~ number_of_primary_shards - 1)之间,文档就在对应的 shard 上。routing 值默认是文档的 _id 的值,也可以手动指定一个值,手动指定对于负载均衡以及提升批量读取的性能都有帮助。
- 正是这种路由机制,导致了 primary shard(主分片)的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索
增删改查时主分片与复制分片如何交互
假设有三个节点的集群。它包含一个叫做bblogs的索引并拥有两个主分片。每个主分片有两个复制分片。相同的分片不会放在同一个节点上,所以我们的集群是这样的:
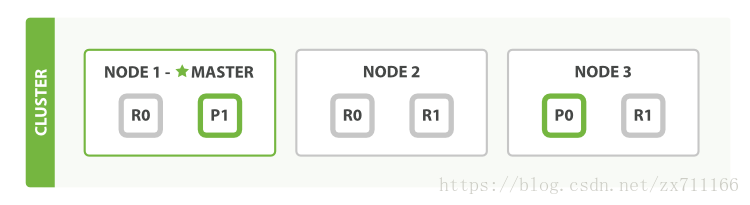
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。下面的例子中,我们将发送所有请求给Node 1,这个节点我们将会称之为请求节点(requesting node)。
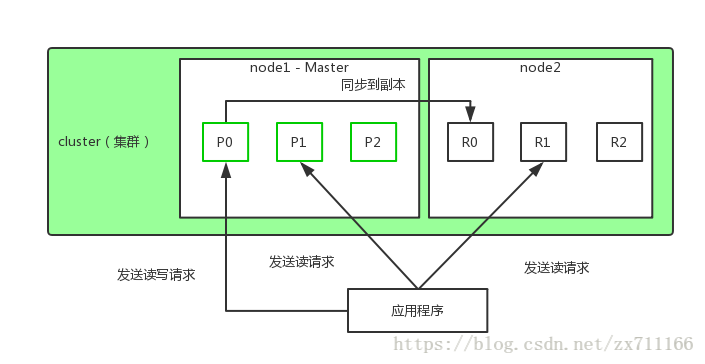
新建、 索引与删除一个文档
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
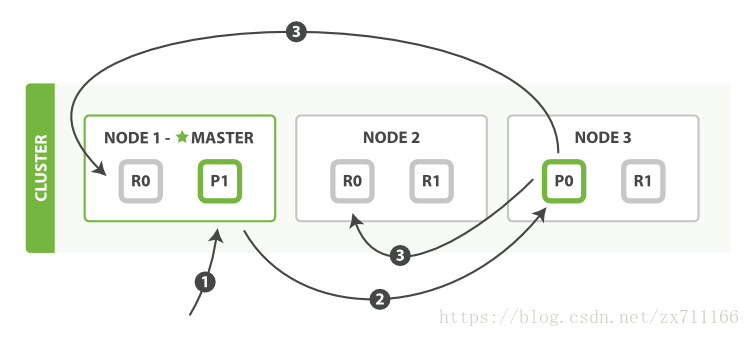
1、客户端发送了一个索引或者删除的请求给node 1。
2、node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中(node 1知道shard 0的primary shard位于node 3节点上),node 1会把这个请求转发到node 3。
3、node 3在shard 0 的primary shard上执行请求。如果请求执行成功,它node 3将并行地将该请求发给shard 0的其余所有replica shard上,也就是存在于node 1和node 2中的replica shard。如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。此时修改已经生效。
有很多可选的请求参数允许你更改这一过程。你可能想牺牲一些安全来提高性能。这一选项很少使用因为Elasticsearch已经足够快,下面将一一阐述。
replication
- 复制默认的值是 sync(同步操作)。这将导致主分片得到复制分片的成功响应后才返回。
- 当 replication 设置为 async(异步操作),请求在主分片上被执行后就会返回给客户端。它依旧会转发请求给复制节点,但你将不知道复制节点成功与否。
- 该选项不建议使用。默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其它分片就绪的情况下发送过多的请求而使Elasticsearch过载。