博主
专辑
- 跟着禹神学Vue3 1
- Vue3+Element Plus 12
- hutool工具包的使用 13
- 学习笔记zg4 25
- javaweb专辑 2
- gradle专辑 1
- 学习笔记zg2 25
- LeetCode学习 1
- Redisson分布式锁架构 4
- 学习笔记zg6 4
- java面试问题扩充 1
- 消息中间件学习 3
- 学习笔记20230815 11
- Vue3编程专辑 3
- 图片 1
- JVM诊断调优工具Arthas 教程到实战 8
- AOP专辑 3
- ChatGPT问答专辑 4
- kafka 1
- HBase数据库专辑 6
- 第三方接口访问方法 5
- 课堂笔记 1
- 分布式文件存储系统MinIO 5
- Linux运维与安全 4
- Kubernetes专辑 2
- 11 1
- VMWare使用专辑 3
- 线程池 1
- Spring面试 1
- Mycat 2
- Spring 自定义注解与Aop 2
- FFmpeg 1
- ElasticSearch 1
- 面试八股文 5
- mysql 1
- Mybatis 1
- docker 1
- vscode开发vue程序的环境配置 3
- DFA 算法实现的高性能 java 敏感词工具框架sensitive-word 3
- 随心笔记 4
- kafka入门专辑 7
- Websocket专辑 2
- Sentinel专辑 7
- 支付宝支付专辑 3
- Java错误集锦 5
- Web Uploader大文件上传专辑 4
- Mybatis 与 MybatisPlus 专辑 4
- oracle 1
- 达梦数据库 1
- 若依框架专辑 4
- FreeMarker专辑 6
- 电商专辑 1
- 专辑 2
- JAVA十八罗汉 1
- SQL优化专题 6
- MyCat专辑 2
- 简单思考 1
- 学习文档 22
- 腾讯云直播专辑 9
- Skywalking链路追踪 3
- Java面试问题专辑 12
- Java常用工具类专辑 10
- java基础技术及功能 2
- PDF专辑 2
- 网站接入第三方微信扫码登录 3
- Seata分布式事务专辑 2
- Activiti工作流专辑 2
- Linux 1
- Mybatis和MybatisPlus杂记 1
- JMeter专辑 2
- 阿里直播专辑 1
- 面试专辑-数据库篇 1
- 微信登录专辑 1
- MySQL编程指南 3
- Jsoup专辑 6
- MySQL专辑 1
- Apache AB入门 3
- Spring事务专辑 3
- 数据库 1
- 算法 2
- Thymeleaf模版专辑 13
- Java数据加密专辑 4
- Spring框架入门教程 2
- maven专题 6
- JVM专题 9
- 面试专辑高级篇 15
- 面试专辑基础篇 15
- SpringBoot集成Excel的导入导出功能 2
- java设计模式 2
- Apache ECharts使用入门 9
- 分布式框架之zookeeper+dubbo 8
- Java面试专辑 2
- Excel 3
- 微信支付入门 18
- SpringCloud-Alibaba入门专辑 14
- Linux服务器环境配置专辑 8
- SpringCloud-Alibaba 3
- redis葵花宝典 4
- nginx服务器系列 9
- FastDFS专辑 4
- 参码电商平台系统 3
- RabbitMQ由入门到精通 11
- mybatis -plus 7
- IDEA使用技能专辑 10
- MongoDB专辑 6
- Elasticsearch专辑 20
- SSM框架 5
- Redis编程指南 1
- Linux系统常用命令的使用 0
- SpringSecurity安全框架 7
- SpringBoot集成Redis编程 4
- Redis入门专辑 28
- Vue编程专辑 39
- 文件上传到阿里云OSS实战 4
- git源码管理专题 12
- HTTP协议简析 4
- Docker环境搭建专辑 32
- SpringBoot微服务编程专辑 51
- SpringCloud微服务架构 20
- svn源码管理专题 0
- Oracle编程指南 0
- Json编程指南 0
- Spring 实战 0
- 华为高斯(GaussDB)数据库专辑 0
- SpringBoot中的Thymeleaf模板入门 0
- 搭建Window的开发环境 0
- Java语言开发笔记 0
- 微信登录接口专辑 0
第二十节 ES聚合查询-es深度分页问题如何解决
第10单元-ES聚合查询-06-es深度分页问题如何解决
项目需求:
大量用户成年累月的发布朋友圈,因此朋友圈有大量的数据,用户在搜索时,要保障无论多少数据,都不影响搜索分页的性能。
需求描述:
大量用户成年累月的发布朋友圈,因此朋友圈有大量的数据,用户在搜索时,要保障无论多少数据,都不影响搜索分页的性能。由于使用from和size分页,会导致性能问题,因此在大量数据的情况,必须使用ES的深度分页来完成。
为什么要用ES的深度分页
Elasticsearch的深度分页是指在处理大量数据时,通过使用scroll API或search_after API来获取大于10000条数据的分页结果。由于Elasticsearch默认的分页大小为10000,当需要获取更多数据时,就需要使用深度分页来处理大量数据。深度分页可以帮助用户有效地处理大规模的数据集,但需要注意的是,深度分页可能会影响性能。因此,在使用深度分页时,需要谨慎考虑性能和资源消耗的平衡。
深度分页的实现方案
Elasticsearch的深度分页有几种实现方案,其中两种比较常见的是使用Scroll API和Search After API。这两种方法都可以用于处理大规模数据的分页查询,但它们在实现和适用场景上有一些区别。
- Scroll API:
- 工作原理: 使用Scroll API时,初始搜索请求会创建一个“快照”,并返回第一页结果和一个scroll_id。之后,通过使用这个scroll_id进行连续的滚动查询,直到获取所有的数据。Scroll的过程中,Elasticsearch会保持搜索上下文的状态,以确保一致性。
- 适用场景: Scroll适用于对数据进行一次性的大规模处理,例如导出所有数据到另一个存储系统。
- Search After API:
- 工作原理: 使用Search After API时,需要提供上一页结果中的最后一个文档的排序值。新的请求会使用这个排序值来获取下一页的结果,从而实现深度分页。相比于Scroll,Search After更加实时,因为每次请求都会重新计算结果。
- 适用场景: Search After适用于需要实时性较高的分页场景,例如在Web应用中展示大量数据的分页。
这两种方法各有优劣,选择取决于具体的使用场景和需求。使用Scroll API时,需要注意在处理完数据后及时清理scroll上下文,以释放资源。而使用Search After API时,要确保排序字段的唯一性,以避免重复或遗漏数据。总体而言,深度分页的选择应该根据实际情况平衡性能和资源消耗。
1、定义实体类
package com.bwie.es;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Date;
/**
* @author 军哥
* @version 1.0
* @description: ES创建索引的实体类
* @date 2024/3/4 8:57
*/
@Data
// indexName 索引的名字 shards 分片的数量 replicas 副本的数量
@Document(indexName = "es_user_info", shards = 1, replicas = 1)
public class EsUserInfo {
@Id
@Field(type = FieldType.Integer)
private Integer userId;
// ik_max_word ik_smart
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String nickName;
@Field(type = FieldType.Keyword)
private String avatar;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String tags;
@Field(type = FieldType.Keyword)
private String gender;
@Field(type = FieldType.Integer)
private Integer age;
private String education;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String city;
@Field(type = FieldType.Keyword)
private String birthday;
@Field(type = FieldType.Keyword)
private String coverPic;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String profession;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String hobby;
@Field(type = FieldType.Keyword)
private String mobile;
@Field(type = FieldType.Keyword)
private String income;
@Field(type = FieldType.Keyword)
private String email;
@Field(type = FieldType.Integer)
private Integer marriage;
@Field(type = FieldType.Integer)
private Integer userLock;
// 实现了数据的时间格式和ES中的时间格式,保持了一致(一样)
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
private Date createTime;
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
private Date updateTime;
}
2、普通分页
/***
* @description 普通分页
* @return com.bwie.utils.R
* @author 军哥
* @date 2024/3/19 11:27
*/
@Override
public R search(PageVo pageVo) {
// 计算起始的页号:ES的分页,是从0开始的
int pageNum = 0;
if(pageVo.getPageNum() > 0) {
pageNum = pageVo.getPageNum() - 1;
}
// 创建分页对象
PageRequest pageRequest = PageRequest.of(pageNum, pageVo.getPageSize());
// 创建ES的查询条件
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
// 添加分页条件:(强调)要使用单独的分页技术
nativeSearchQueryBuilder.withPageable(pageRequest);
// 添加排序
FieldSortBuilder sortBuilderUserId = new FieldSortBuilder("userId").order(SortOrder.DESC);
nativeSearchQueryBuilder.withSort(sortBuilderUserId);
// 创建全局的查询条件
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
// 添加根据用户昵称来搜索
if(!StringUtils.isEmpty(pageVo.getKeyWord())) {
// must==and
// matchQuery 分词查找
// termQuery 精确查找
// fuzzyQuery 模糊查询
boolQueryBuilder.must(QueryBuilders.termQuery("nickName", pageVo.getKeyWord()));
}
// 添加ES的高亮:用户昵称实现高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("nickName").preTags("<font color='red'>").postTags("</font>");
nativeSearchQueryBuilder.withHighlightBuilder(highlightBuilder);
// 根据年龄区间进行查找:(根据数值类型进行区间查找)
// gte 大于等于
// lte 小于等于
// gt 大于
// lt 小于
// eq 等于
if(pageVo.getStartNum() != null && pageVo.getEndNum() != null) {
boolQueryBuilder.must(
QueryBuilders.rangeQuery("age")
.gte(pageVo.getStartNum())
.lte(pageVo.getEndNum())
);
}
// 根据用户的注册时间进行区间查询:时间的区间查询和数值的时间查询不一样
// 时间查询的参数,一定要定义为字符串类型
if(pageVo.getBeginTime() != null && pageVo.getEndTime() != null) {
boolQueryBuilder.must(
QueryBuilders
.rangeQuery("createTime")
.format("yyyy-MM-dd HH:mm:ss")
.timeZone("GMT+8")
.gte(pageVo.getBeginTime())
.lte(pageVo.getEndTime())
);
}
// 开始查询
nativeSearchQueryBuilder.withQuery(boolQueryBuilder);
SearchHits<EsUserInfo> searchHits = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), EsUserInfo.class);
// 解析查询的结果
// 符合条件的记录数:
long totalHits = searchHits.getTotalHits();
ArrayList<EsUserInfo> records = new ArrayList<>();
List<SearchHit<EsUserInfo>> hits = searchHits.getSearchHits();
for (SearchHit<EsUserInfo> hit : hits) {
EsUserInfo esUserInfo = hit.getContent();
// 获取高亮字段
List<String> nickNameList = hit.getHighlightField("nickName");
if( nickNameList!= null && nickNameList.size()>0) {
// 获取包含高亮的信息
String nickName = hit.getHighlightField("nickName").get(0);
// 使用高亮的信息替换原来的数据
esUserInfo.setNickName(nickName);
}
records.add(esUserInfo);
}
// 返回分页的信息:最好的方式是和MybatisPlus结构是一样
HashMap<String, Object> map = new HashMap<>();
map.put("total", totalHits);
map.put("pageNum", pageNum + 1);
map.put("pageSize", pageVo.getPageSize());
map.put("records", records);
return R.SUCCESS(map);
}
3、游标分页(Scroll API)
@Test
public void performScrollSearch() {
// 每次滚动获取的文档数量
int pageSize = 10;
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(matchAllQuery())
.withPageable(PageRequest.of(0, pageSize))
.build();
// scroll游标快照超时时间,单位ms
long scrollTimeInMillis = 60 * 1000;
String scrollId = null;
// 开始查询
SearchScrollHits<EsUserInfo> searchScrollHits = elasticsearchRestTemplate.searchScrollStart(
scrollTimeInMillis,
searchQuery,
EsUserInfo.class,
IndexCoordinates.of("es_user_info")
);
scrollId = searchScrollHits.getScrollId();
int page = 1;
do {
for (SearchHit<EsUserInfo> searchHit : searchScrollHits.getSearchHits()) {
EsUserInfo content = searchHit.getContent();
System.out.println("name:" + content.getNickName());
}
System.out.println("============== page " + page + " ====================");
page ++;
// 下一个查询
searchScrollHits = elasticsearchRestTemplate.searchScrollContinue(scrollId,
scrollTimeInMillis, EsUserInfo.class, IndexCoordinates.of("es_user_info"));
} while (searchScrollHits.hasSearchHits());
// 清除 scroll
List<String> scrollIds = new ArrayList<>();
scrollIds.add(scrollId);
elasticsearchRestTemplate.searchScrollClear(scrollIds);
}
4、Search After API
创建一个springboot项目
1、导入对应的依赖
<dependencies>
<!--elasticsearch需要的包-->
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-data-elasticsearch</artifactId>-->
<!-- </dependency>-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.4.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>6.4.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<!--版本保持一致,不然缺类-->
<version>6.4.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
</dependencies>
2、实体类User
package com.example.demo.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User {
private String name;
private Integer age;
}
3、ElasticSearchClientConfig来配置一个相应的类
package com.example.demo.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http")));
return client;
}
}
4、写一个测试类去测试
package com.example.demo;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class DemoApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
}
5、创建索引
//测试创建索引
@Test
public void contextLoads() throws IOException {
//创建 索引"weifan" 请求
CreateIndexRequest request = new CreateIndexRequest("weifan");
//客户端执行请求,并获得相应
CreateIndexResponse createIndexResponse
= client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
6、获取索引
//测试获取索引
@Test
public void testExistIndex() throws IOException{
// GetRequest request=new GetRequest("weifan","","");
// boolean exists = client.exists(request, RequestOptions.DEFAULT);
// System.out.println(exists);
//1、创建请求对象
GetIndexRequest request=new GetIndexRequest();
request.indices("weifan");
//判断
boolean exists
= client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
7、删除索引
//测试删除索引
@Test
public void testDeleteIndex() throws IOException{
DeleteIndexRequest request=new DeleteIndexRequest("weifan");
DeleteIndexResponse delete = client.indices().delete(request,RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
8、添加文档
@Test
public void testAddDocument() throws IOException {
User user = new User("狂神说", 3);
//创建索引请求
IndexRequest request= new IndexRequest("kuangshen");
//IndexRequest request1=new IndexRequest("kuangshen","User","1");
//kibana 会用 put/kuangshen/User/1 添加数据
// {
// "name":"狂神说",
// "age":23
// }
request.type("User");
request.id("1");
//将我们的数据放入请求json中(指定添加的数据)
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.getIndex());//kuangshen
System.out.println(indexResponse.toString());//IndexResponse[index=kuangshen,type=User,id=1,version=1,result=created,seqNo=0,primaryTerm=1,shards={"total":2,"successful":1,"failed":0}]
System.out.println(indexResponse.status());//对应我们命令返回状态是CREATED
}
9、获取文档,判断是否存在
@Test
public void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("kuangshen","User", "1");
boolean exists = client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
10、获取文档信息
@Test
public void testGetDocument() throws IOException{
GetRequest getRequest = new GetRequest("kuangshen","User", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
//打印文档的内容
System.out.println(getResponse.getSourceAsString());//{"age":3,"name":"狂神说"}
System.out.println(getResponse);//{"_index":"kuangshen","_type":"User","_id":"1","_version":1,"found":true,"_source":{"age":3,"name":"狂神说"}}
}
11、更新文档信息
//更新文档信息
@Test
public void testUpdateRequest() throws IOException {
UpdateRequest updateRequest=new UpdateRequest("kuangshen","User","1");
updateRequest.timeout("1s");
User user=new User("狂神说Java",18);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());//OK
System.out.println(updateResponse.toString());//UpdateResponse[index=kuangshen,type=User,id=1,version=2,seqNo=-2,primaryTerm=0,result=noop,shards=ShardInfo{total=0, successful=0, failures=[]}]
System.out.println(updateResponse);
}
12、删除文档记录
@Test
public void testDeleteRequest() throws IOException {
DeleteRequest request = new DeleteRequest("kuangshen","User", "1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
13、批量插入数据
@Test
public void testBulkRequest() throws IOException {
BulkRequest bulkRequest=new BulkRequest();
bulkRequest.timeout("10s");
List<User> userList=new ArrayList<>();
userList.add(new User("weifan1",3));
userList.add(new User("weifan2",3));
userList.add(new User("weifan3",3));
userList.add(new User("weifan4",3));
//批处理
for(int i=0;i<userList.size();i++){
bulkRequest.add(
new IndexRequest("kuangshen")
.type("User")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());
}
14、查询
例14.1
//查询
@Test
public void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("kuangshen");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//sourceBuilder.sort() 排序查询
//查询条件,我们可以使用QueryBuilders工具来实现
//QueryBuilders.termQuery() 精确
//QueryBuilders.matchAllQuery() 匹配所有
//QueryBuilders.fuzzyQuery() 模糊查询
//QueryBuilders.rangeQuery() 范围查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "weifan1");
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
//结果:{"fragment":true,"hits":[{"fields":{},"fragment":false,"highlightFields":{},"id":"1","matchedQueries":[],"score":0.2876821,"sortValues":[],"sourceAsMap":{"name":"weifan1","age":3},"sourceAsString":"{\"age\":3,\"name\":\"weifan1\"}","sourceRef":{"childResources":[],"fragment":true},"type":"User","version":-1}],"maxScore":0.2876821,"totalHits":1}
System.out.println("=====================");
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
System.out.println(documentFields.getSourceAsString());//{"age":3,"name":"weifan1"}
//System.out.println(documentFields.getSourceAsMap());
}
}
例14.2
/**
* ##搜索address中包含mill的所有年龄分布和平均年龄
* GET bank/_search
* {
* "query":{
* "match": {
* "address":"mill"
* }
* },
* "aggs": {
* "ageAgg": {
* "terms": {
* "field": "age",
* "size": 10
* }
* },
* "ageAvg":{
* "avg": {
* "field": "age"
* }
* }
* }
* }
* */
@Test
public void searchData() throws IOException {
SearchRequest searchRequest = new SearchRequest("bank");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("address", "mill"));
TermsAggregationBuilder aggregation = AggregationBuilders.terms("ageAgg")//Aggregations聚合
.field("age").size(10);
aggregation.subAggregation(AggregationBuilders.avg("ageAvg")
.field("age"));
searchSourceBuilder.aggregation(aggregation);
searchRequest.source(searchSourceBuilder);
System.out.println(searchRequest);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse);
}
15、分页查询(from-size 适用于浅分页;分页越深,性能越差)
rom-size浅分页适合数据量不大的情况(官网推荐是数据少于10000条)
详细请见官网:https://www.elastic.co/guide/cn/elasticsearch/guide/2.x/_query_phase.html
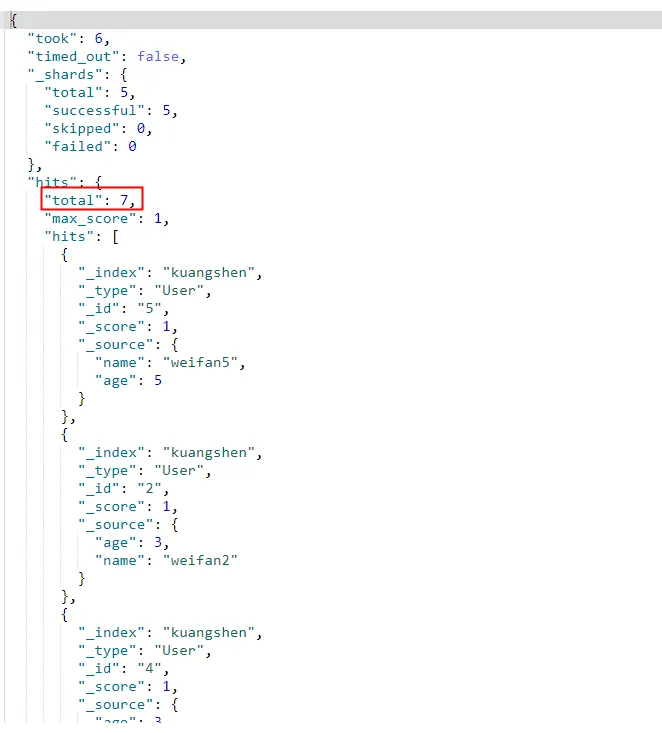
从下图可知es中有7条数据
//分页查询
@Test
public void testSearchByPage1() throws IOException {
Integer currentPage=1;
Integer pageSize=3;
SearchRequest searchRequest=new SearchRequest();
searchRequest.indices("kuangshen");
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
/**
* 浅分页
* GET /_search{
* "from":0
* "size":3
*}
*/
searchSourceBuilder.from(currentPage-1);
searchSourceBuilder.size(pageSize);
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(response.getHits()));
System.out.println("------------------------------------------------------");
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit:hits) {
System.out.println(hit.getSourceAsString());
}
}
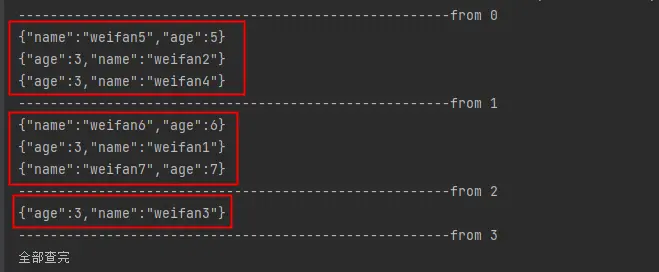
//浅分页多次查询(from-size)
@Test
public void testSearchByPage2() throws IOException {
Integer currentPage=1;
Integer pageSize=3;
SearchRequest searchRequest=new SearchRequest();
searchRequest.indices("kuangshen");
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
searchSourceBuilder.from(currentPage-1);
searchSourceBuilder.size(pageSize);
Boolean hasMore=true;
while (hasMore){
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
//System.out.println(JSON.toJSONString(response.getHits()));
System.out.println("------------------------------------------------------"+"from "+ Integer.toString(currentPage-1));
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit:hits) {
System.out.println(hit.getSourceAsString());
}
if(hits.length==0){//返回没值时,则表示遍历完成
hasMore=false;
}
currentPage++;
searchSourceBuilder.from((currentPage-1)*pageSize);
searchSourceBuilder.size(pageSize);
}
System.out.println("全部查完");
}
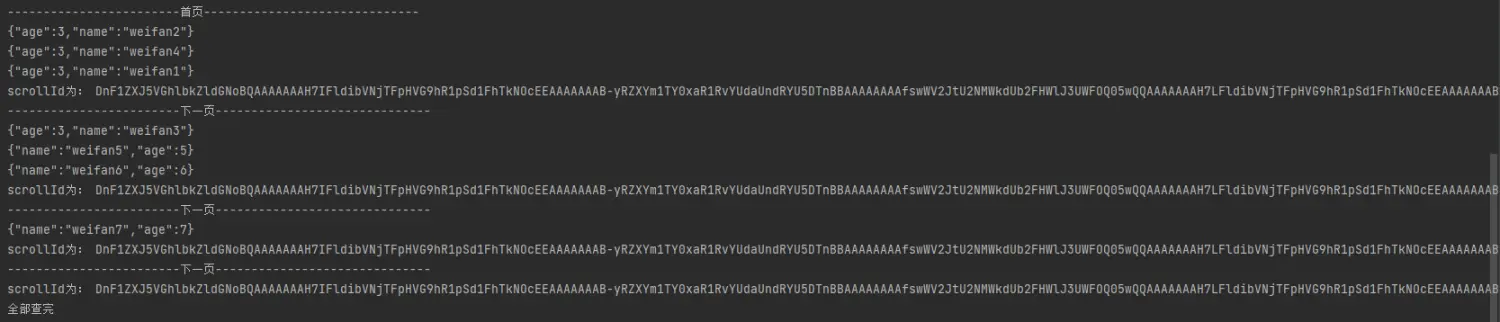
16、深分页(scroll【还有一种search_after方法】)
//多次分页查询(scroll)
@Test
public void testSearchByPage3() throws IOException {
//Integer currentPage=1;
Integer pageSize=3;
SearchRequest searchRequest=new SearchRequest();
searchRequest.indices("kuangshen");
searchRequest.scroll(TimeValue.timeValueMinutes(1L));//设置scroll失效时间为1分钟
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
//不需要传从第几条开始
//searchSourceBuilder.from(currentPage-1);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.sort("age", SortOrder.ASC);//排序,查出来的数据根据age排序
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
//System.out.println(JSON.toJSONString(response.getHits()));
System.out.println("------------------------首页------------------------------");
SearchHit[] hits = response.getHits().getHits();
for (SearchHit hit:hits) {
System.out.println(hit.getSourceAsString());
}
String scrollId=response.getScrollId();
System.out.println("scrollId为: "+response.getScrollId());
Boolean hasMore=true;
while (hasMore){
SearchScrollRequest searchScrollRequest=new SearchScrollRequest();
searchScrollRequest.scroll(TimeValue.timeValueMinutes(1L));
searchScrollRequest.scrollId(scrollId);
SearchResponse scrollResponse = client.scroll(searchScrollRequest, RequestOptions.DEFAULT);
System.out.println("------------------------下一页------------------------------");
SearchHit[] hits1 = scrollResponse.getHits().getHits();
for (SearchHit hit:hits1) {
System.out.println(hit.getSourceAsString());
}
if(hits1.length==0){//返回没值时,则表示遍历完成
hasMore=false;
}
scrollId = scrollResponse.getScrollId();
System.out.println("scrollId为: "+scrollId);
}
System.out.println("全部查完");
}
16、from+size 和 scroll两种方式比较

scroll用的是快照模式,有个窗口期,都是基于这个窗口期的快照来做的查询,scrollId对应的就是这个快照,scrollId是不变的
17、elasticsearch scroll查询的原理
1、https://elasticsearch.cn/question/2935
2、https://www.elastic.co/guide/cn/elasticsearch/guide/2.x/_fetch_phase.html
3、https://www.jianshu.com/p/91d03b16af77