好的,若依框架(RuoYi)基于 Spring Boot 和 MyBatis,配置读写分离非常方便。它底层依赖于 Spring 内置的抽象 AbstractRoutingDataSource 来实现动态数据源路由。
以下是手动配置若依框架读写分离的详细步骤。
方法一:手动配置(理解原理)
这种方法让你完全掌控配置过程,适合理解其底层原理。
第1步:配置多数据源
在 ruoyi-admin 模块的 application.yml (或 application-druid.yml) 配置文件中,配置主库和从库的连接信息。
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
# 主库数据源 (用于写操作)
master:
url: jdbc:mysql://localhost:3306/ry?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: master_password
# 从库数据源 (用于读操作,如果有多个从库,用slave1, slave2...即可)
slave:
url: jdbc:mysql://192.168.1.101:3306/ry?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: slave_password
第2步:创建数据源配置类
这个类是核心,它负责:
1. 创建主、从数据源对象。
2. 创建动态数据源 DynamicDataSource,并设置数据源映射。
3. 设置动态数据源作为主数据源。
package com.ruoyi.framework.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.ruoyi.framework.datasource.DynamicDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DataSourceConfig {
/**
* 主库数据源
*/
@Bean
@ConfigurationProperties("spring.datasource.master")
public DataSource masterDataSource() {
return new DruidDataSource();
}
/**
* 从库数据源
*/
@Bean
@ConfigurationProperties("spring.datasource.slave")
public DataSource slaveDataSource() {
return new DruidDataSource();
}
/**
* 核心:动态数据源
*/
@Bean
@Primary // 标识为主数据源,这样Spring容器在注入DataSource时会优先使用这个
public DynamicDataSource dataSource(DataSource masterDataSource, DataSource slaveDataSource) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
targetDataSources.put(DataSourceType.SLAVE.name(), slaveDataSource);
// 创建动态数据源,并设置默认数据源为主库
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(masterDataSource);
return dynamicDataSource;
}
}
第3步:定义数据源枚举和上下文持有者
你需要一个枚举来标识数据源,以及一个线程本地变量(ThreadLocal)来为每个请求“记住”应该使用哪个数据源。
数据源枚举:
package com.ruoyi.framework.datasource;
/**
* 数据源枚举
*/
public enum DataSourceType {
/**
* 主库
*/
MASTER,
/**
* 从库
*/
SLAVE
}
数据源上下文持有者:
package com.ruoyi.framework.datasource;
/**
* 数据源上下文持有者 (用于切换数据源)
*/
public class DataSourceContextHolder {
// 使用 ThreadLocal 保证线程安全,为每个请求单独存储数据源标识
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 设置数据源
*/
public static void setDataSourceType(String dsType) {
CONTEXT_HOLDER.set(dsType);
}
/**
* 获取数据源
*/
public static String getDataSourceType() {
return CONTEXT_HOLDER.get();
}
/**
* 清空数据源 (非常重要,在请求结束后清理,防止内存泄漏和误用)
*/
public static void clearDataSourceType() {
CONTEXT_HOLDER.remove();
}
}
第4步:创建动态数据源类
这个类继承 AbstractRoutingDataSource,它的 determineCurrentLookupKey() 方法是决定使用哪个数据源的**关键**。
package com.ruoyi.framework.datasource;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import javax.sql.DataSource;
import java.util.Map;
/**
* 动态数据源
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
public DynamicDataSource() {}
/**
* 核心方法:决定当前线程应该使用哪个数据源
* 返回的值,就是在 DataSourceConfig 中 targetDataSources Map 的 Key
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.getDataSourceType();
}
}
第5步:创建 AOP 切面实现自动切换
这是实现“读操作用从库,写操作用主库”自动化逻辑的地方。
package com.ruoyi.framework.aspectj;
import com.ruoyi.framework.datasource.DataSourceContextHolder;
import com.ruoyi.framework.datasource.DataSourceType;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.core.annotation.AnnotationUtils;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import java.util.Objects;
/**
* 数据源切换切面
*/
@Aspect
@Component
@Order(1) // 保证在事务切面之前执行
public class DataSourceAspect {
/**
* 切点:拦截所有 Service 层的方法
*/
@Pointcut("execution(* com.ruoyi..*.service..*(..))")
public void dataSourcePointCut() {}
@Around("dataSourcePointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
// 1. 尝试获取方法上的 @DataSource 注解
MethodSignature signature = (MethodSignature) point.getSignature();
DataSource dataSourceAnnotation = AnnotationUtils.findAnnotation(signature.getMethod(), DataSource.class);
// 2. 如果方法上没有,再尝试获取类上的 @DataSource 注解
if (Objects.isNull(dataSourceAnnotation)) {
dataSourceAnnotation = AnnotationUtils.findAnnotation(signature.getDeclaringType(), DataSource.class);
}
// 3. 判断注解是否存在,并决定使用哪个数据源
try {
if (Objects.nonNull(dataSourceAnnotation)) {
// 如果方法或类上明确指定了数据源,则使用指定的
DataSourceContextHolder.setDataSourceType(dataSourceAnnotation.value().name());
} else {
// 默认规则:根据方法名判断
String methodName = point.getSignature().getName();
// 如果方法名以 get, select, find, query 等开头,则使用从库
if (methodName.startsWith("get") || methodName.startsWith("select") ||
methodName.startsWith("find") || methodName.startsWith("query") ||
methodName.startsWith("search") || methodName.startsWith("count")) {
DataSourceContextHolder.setDataSourceType(DataSourceType.SLAVE.name());
} else {
// 否则(insert, update, delete, save等)使用主库
DataSourceContextHolder.setDataSourceType(DataSourceType.MASTER.name());
}
}
// 4. 执行原方法
return point.proceed();
} finally {
// 5. 非常重要:在方法执行完毕后,清空数据源标识,恢复为默认数据源(主库)
DataSourceContextHolder.clearDataSourceType();
}
}
}
第6步:(可选)创建自定义注解用于手动指定数据源
对于某些特殊场景,你可能想强制某个方法使用主库或从库。
package com.ruoyi.framework.datasource;
import java.lang.annotation.*;
/**
* 自定义数据源注解
*/
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DataSource {
DataSourceType value() default DataSourceType.MASTER;
}
使用示例:
@Service
public class UserServiceImpl implements IUserService {
// 这个查询方法强制走主库,用于解决“写完立即读”的数据一致性问题
@DataSource(DataSourceType.MASTER)
@Override
public SysUser selectUserById(Long userId) {
return userMapper.selectUserById(userId);
}
}
方法二:使用若依内置的多数据源功能(更快捷)
实际上,若依框架从某个版本开始已经内置了多数据源支持,配置起来更简单。
-
在
application-druid.yml中取消注释并配置多数据源# 数据源配置 spring: datasource: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.cj.jdbc.Driver # 主库数据源 master: url: jdbc:mysql://localhost:3306/ry?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8 username: your_username password: your_password # 从库数据源 slave: # 从数据源开关/默认关闭 enabled: true # !!!关键:开启从库 url: jdbc:mysql://192.168.1.101:3306/ry?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8 username: your_username password: your_password -
使用若依提供的
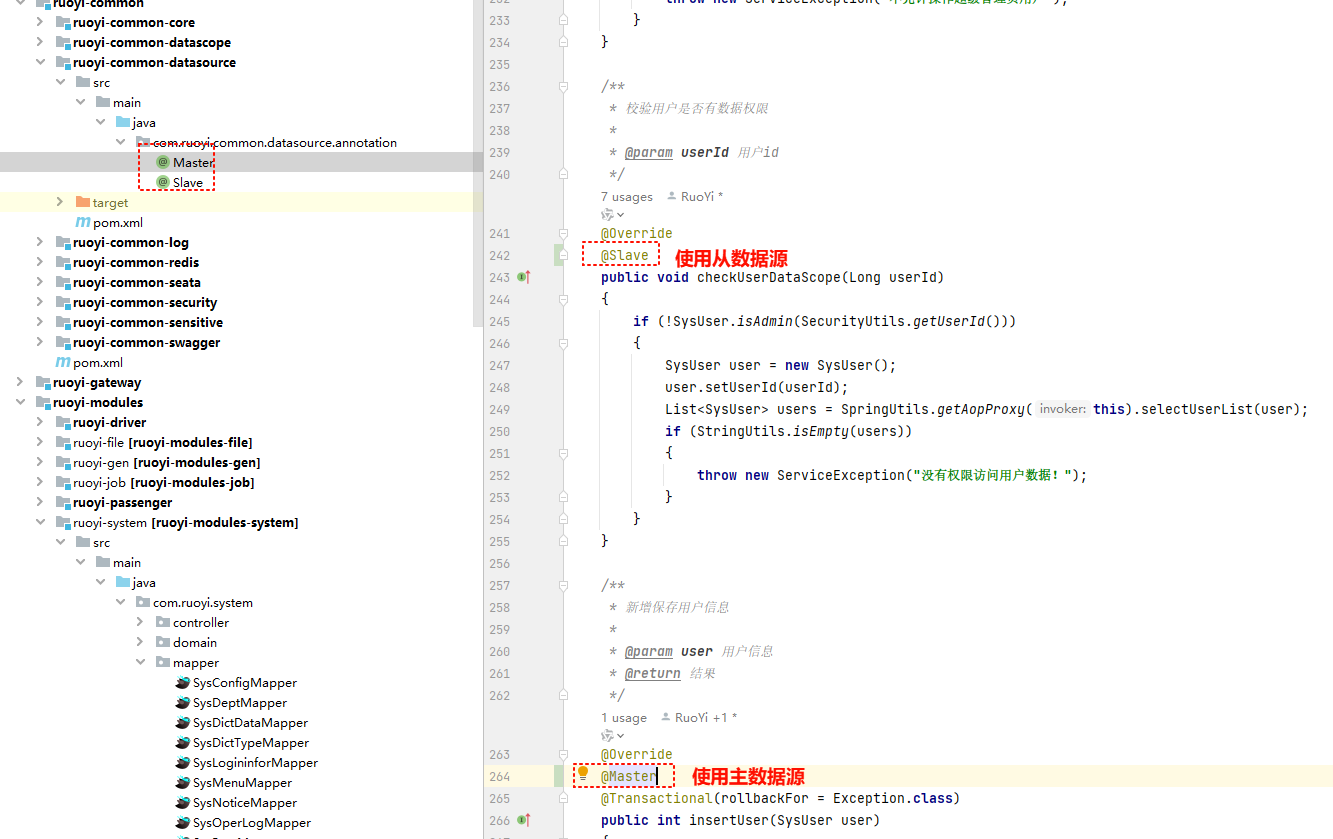
@DataSource注解
若依已经提供了com.ruoyi.framework.aspectj.DataSource注解,你只需要在 Service 层的方法或类上使用它即可。- 不加注解:默认使用主库。
@DataSource(DataSourceType.MASTER): 强制使用主库。@DataSource(DataSourceType.SLAVE): 强制使用从库。
@DataSource(DataSourceType.SLAVE)。
总结与注意事项
- 事务问题:确保数据源切面
@Order的优先级**高于**事务切面@Transactional,否则数据源切换会失效(因为事务管理器在切面之前就已经确定了数据源)。 - 清理上下文:务必在
finally块中调用DataSourceContextHolder.clearDataSourceType(),否则可能导致数据源污染,后续请求错误地使用了上一个请求的数据源。 - 读写分离延迟:主从同步存在毫秒级延迟。对于“写入后立即读取”的场景,请使用
@DataSource(DataSourceType.MASTER)注解强制该读操作走主库。 - 多从库负载均衡:上述示例只有一个从库。如果需要多个从库并做负载均衡,需要在
DynamicDataSource中维护一个从库列表,并在 AOP 或一个专门的LoadBalance策略中轮询或随机选择一个从库。
推荐做法:先尝试使用**方法二(若依内置功能)**,如果不能满足你的自动路由需求,再参考**方法一**来自定义 AOP 切面的路由逻辑。
最新的版本已经使用Master和Slave两个注解了